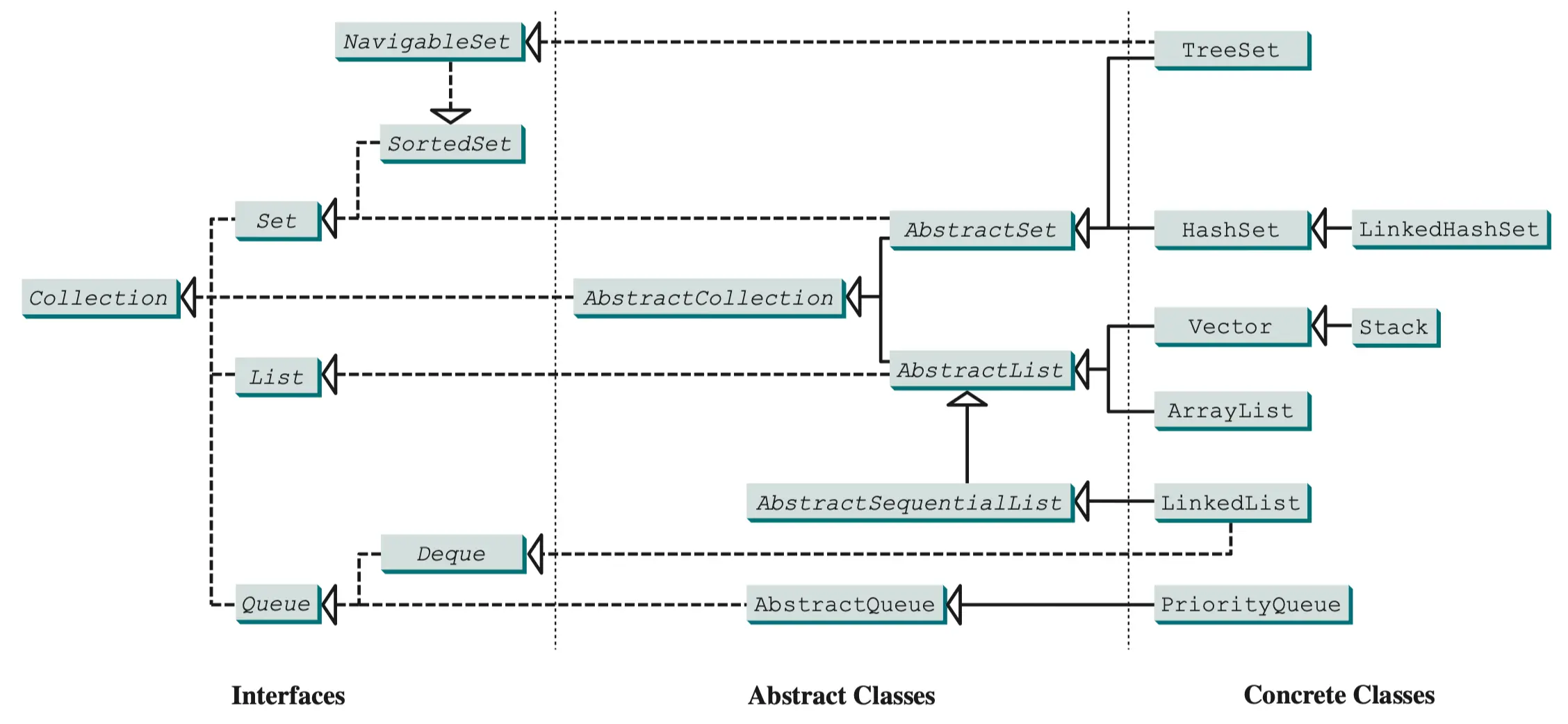
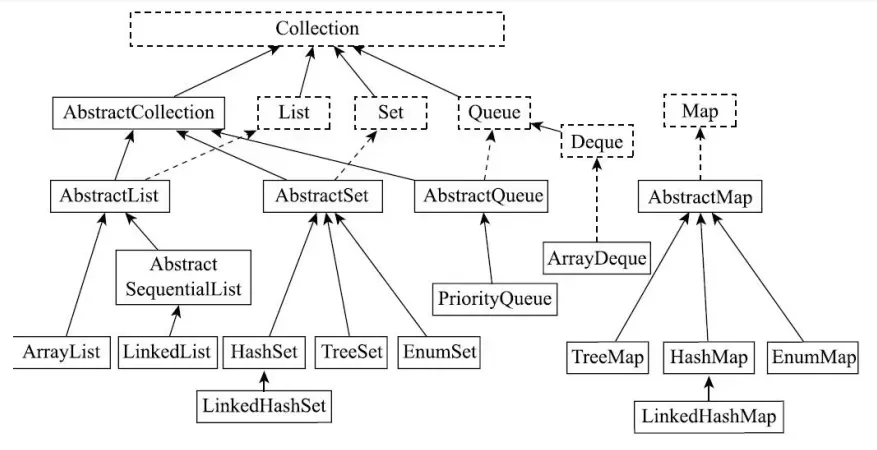
迭代器
Info
迭代器(Iterator)是一种经典的设计模式,用于在不需要暴露数据是如何保存在数据结构中的细节的情况下,遍历一个数据结构。
可以使用 foreach 循环来遍历任何 Co1lection 实例中的元素吗?
在 Java 中,foreach 循环(也称为增强型 for 循环)可以用来遍历实现了 Iterable 接口的集合(Collection 实例),但不能直接用于所有类型的集合或容器。以下是对问题的详细分析和解答:
1. foreach 循环的工作原理
foreach 循环是 Java 提供的一种简化语法,用于遍历实现了 Iterable 接口的对象。其基本语法如下:
for (ElementType element : collection) {
// 对元素进行操作
}这里的 collection 必须是一个实现了 Iterable<T> 接口的对象。Iterable 接口定义了一个方法 iterator(),该方法返回一个 Iterator<T>,用于逐个访问集合中的元素。
2. Collection 接口与 Iterable 的关系
Java 中的 Collection 接口继承了 Iterable 接口,因此所有实现了 Collection 接口的类(如 List、Set 和 Queue 等)都可以使用 foreach 循环来遍历其元素。
例如:
List<String> list = Arrays.asList("A", "B", "C");
for (String item : list) {
System.out.println(item);
}上述代码可以正常运行,因为 List 是 Collection 的子接口,并且实现了 Iterable。
3. 特殊情况:数组
虽然数组不是 Collection 的实例,也不是 Iterable 的实现类,但 Java 特别支持对数组使用 foreach 循环。例如:
int[] numbers = {1, 2, 3, 4};
for (int number : numbers) {
System.out.println(number);
}这种支持是编译器层面的优化,底层会将数组的 foreach 循环转换为基于索引的普通 for 循环。
4. 限制条件
尽管 foreach 循环非常方便,但它也有一些限制:
a) 需要实现 Iterable 接口
如果某个类没有实现 Iterable 接口,则无法直接使用 foreach 循环。例如,自定义的类如果不实现 Iterable,则不能直接用 foreach 遍历其内容。
示例:
class MyCustomClass {
private String[] data = {"A", "B", "C"};
}
MyCustomClass obj = new MyCustomClass();
// 下面代码会报错,因为 MyCustomClass 没有实现 Iterable 接口
for (String item : obj) {
System.out.println(item);
}解决方法是让 MyCustomClass 实现 Iterable 接口,并提供一个 iterator() 方法。
b) 不可修改结构
在使用 foreach 循环时,不能对集合本身进行结构性修改(如添加或删除元素)。如果尝试这样做,可能会抛出 ConcurrentModificationException 异常。
示例:
List<String> list = new ArrayList<>(Arrays.asList("A", "B", "C"));
for (String item : list) {
if (item.equals("B")) {
list.remove(item); // 可能抛出异常
}
}解决方法是使用显式的 Iterator 并调用其 remove() 方法:
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
if (item.equals("B")) {
iterator.remove(); // 安全地移除元素
}
}5. 总结
- 可以使用
foreach循环遍历任何Collection实例,因为Collection接口继承了Iterable。 - 数组也可以使用
foreach循环,这是 Java 的特殊支持。 - 自定义类需要实现
Iterable接口才能使用foreach。 - 在
foreach循环中不能直接修改集合的结构,否则可能引发异常。
线性表
数组线性表类ArrayList 和链表类LinkedList是实现List接口的两个具体类。
ArrayList 用数组存储元素,这个数组是动态创建的。如果元素个数超过了数组的容量,就创建一个更大的新数组,并将当前数组中的所有元素都复制到新数组中。LinkedList 在一个链表中存储元素。
LinkedList 是 List 接口的链表实现。除了实现 List接口外,这个类还提供从线性表两端获取、插人和删除元素的方法。
Summary
在线性表的起始位置插人和删除元素,LinkedList 的效率会高一些; ArrayList 对于所有其他的操作效率会高一些。1
Comparator接口
[list2tab]
-
lambda
Comparator.comparing(e -> e.length ()) -
匿名内部类
Comparator.comparing( new java.util.function.Function<String, Integer>() { public Integer apply(String s) { return s.length(); } } )); -
方法引用
Comparator.comparing(String::length)
默认的 reverse()方法可以反转比较器的顺序。例如,下面的代码以递减的顺序基于1oanAmount 属性对 Load 对象列表进行排序。
Arrays.sort(list, Comparator.comparing(Loan::getLoanAmount).reverse());import java.util.*;
class Student {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Student{name='" + name + "', age=" + age + "}";
}
}
public class ComparatorExample {
public static void main(String[] args) {
// 创建学生列表
List<Student> students = new ArrayList<>();
students.add(new Student("Alice", 20));
students.add(new Student("Bob", 22));
students.add(new Student("Charlie", 20));
students.add(new Student("David", 21));
// 定义一个自定义比较器:先按年龄升序,再按名字字母顺序
Comparator<Student> studentComparator = new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
// 先按年龄比较
if (s1.getAge() != s2.getAge()) {
return Integer.compare(s1.getAge(), s2.getAge());
}
// 如果年龄相同,按名字比较
return s1.getName().compareTo(s2.getName());
}
};
// 使用Comparator对列表进行排序
students.sort(studentComparator);
// 打印排序后的学生列表
System.out.println("排序后的学生列表:");
for (Student student : students) {
System.out.println(student);
}
}
}Vector和Stack
- 对于许多不需要同步的应用程序来说,使用
ArrayList比使用Vector效率更高。 - 在Java 集合框架中,栈类
Stack是作为Vector类的扩展来实现的
队列和优先队列
- 队列是一种先进先出的数据结构。元素被追加到队列末尾,然后从队列头删除。在优先队列中,元素被赋予优先级。当访问元素时,拥有最高优先级的元素首先被删除。
Queue 接口
offer()用于向队列添加一个元素- 方法
pop()和方法remove()类似,但是如果队列为空,方法pop()(会返回nul1,而方法remove()会抛出一个异常。 - 方法
peek()和方法element()类似,但是如果队列为空,方法peek()会返回null, 而方法element()会抛出一个异常。
双端队列 Deque 和链表 LinkedList
LinkedList 类实现了 Deque 接口,Deque 又继承自 Queue 接口,如图所示。因此, 可以使用LinkedList 创建一个队列。LinkedList 很适合用于进行队列操作,因为它可以高效地在列表的两端插入和移除元素。
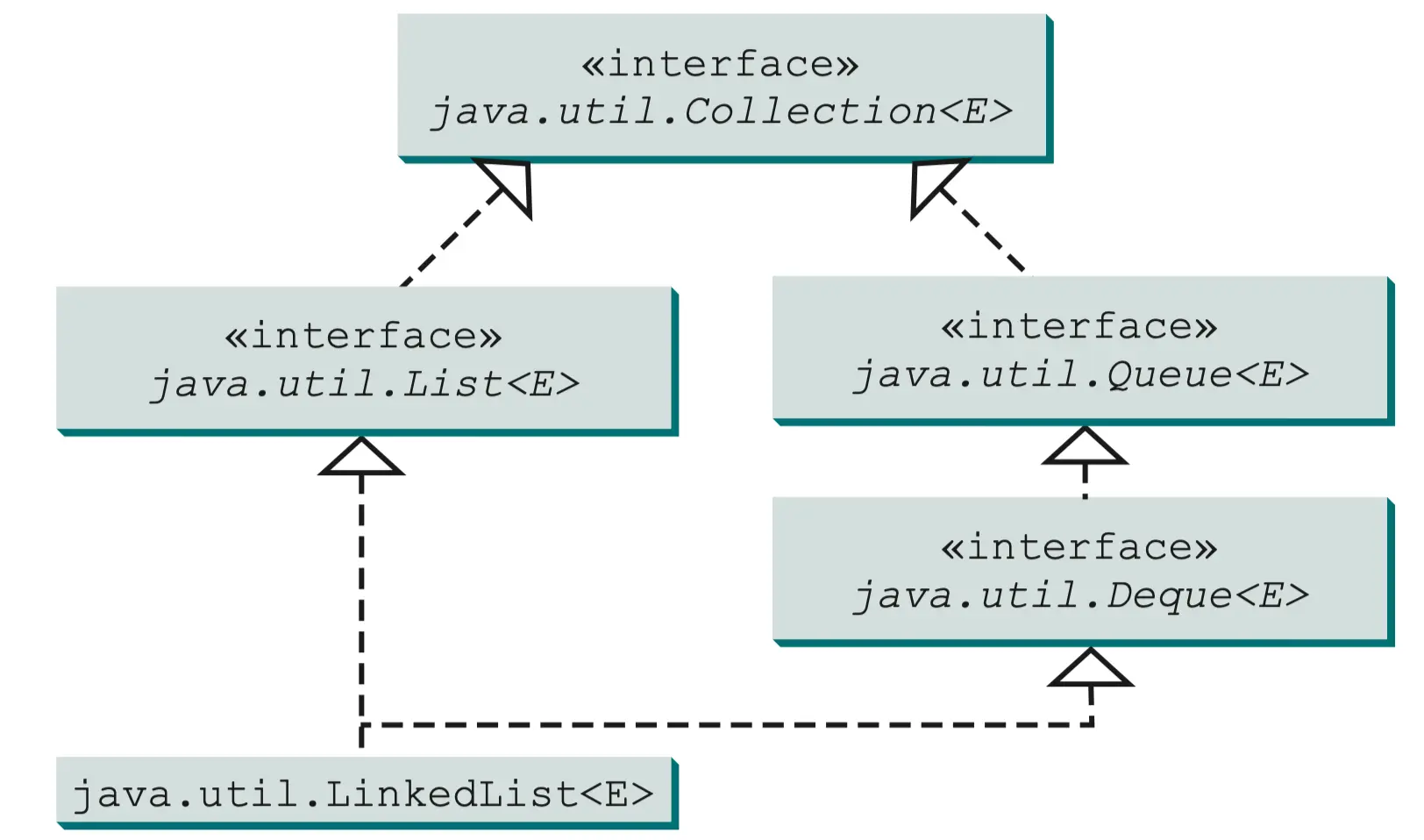
PriorityQueue 类实现了一个优先队列,如图所示。默认情况下,优先队列使用Comparable 以元素的自然顺序^[升序]进行排序。拥有最小数值的元素被赋予最高优先级,因此最先从队列中删除。如果几个元素具有相同的最高优先级,则任意选择一个。也可以使用构造方法 PriorityQveue(initialCapacity,comparator)中的Comparator 来指定一个顺序。
import java.util.*;
public class Main {
public static void main(String[] args) {
// 使用默认的自然顺序(基于String的compareTo方法)
PriorityQueue<String> queue1 = new PriorityQueue<>();
queue1.offer("Oklahoma");
queue1.offer("Indiana");
queue1.offer("Georgia");
queue1.offer("Texas");
System.out.println("Priority queue using Comparable:");
while (queue1.size() > 0) {
System.out.print(queue1.remove() + " ");
}
// 使用自定义的Comparator(反转顺序)
PriorityQueue<String> queue2 = new PriorityQueue<>(4, Collections.reverseOrder());
queue2.offer("Oklahoma");
queue2.offer("Indiana");
queue2.offer("Georgia");
queue2.offer("Texas");
System.out.println("\nPriority queue using Comparator:");
while (queue2.size() > 0) {
System.out.print(queue2.remove() + " ");
}
}
}Priority queue using Comparable:
Georgia Indiana Oklahoma Texas
Priority queue using Comparator:
Texas Oklahoma Indiana Georgia Set
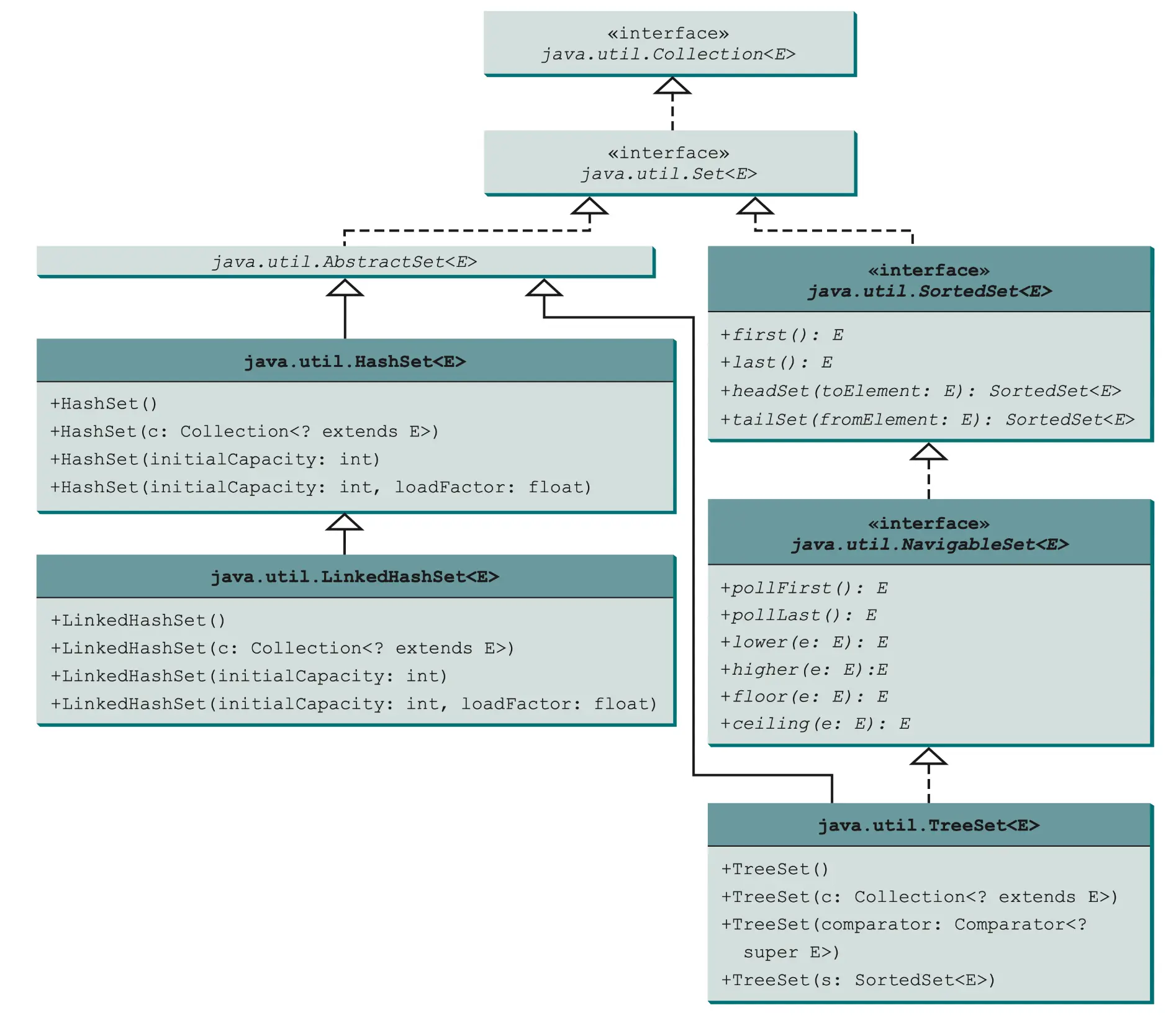
HashSet
Info
- 默认情况下,初始容量为16而负载系数是0.75。如果知道规则集的大小,就可以在构造方法中指定初始容量和负载系数。否则,就使用默认的设置,负载系数的值在0.0~1.0之间。
- 负载系数(load factor)测量该规则集允许填充多满。当元素个数超过了容量与负载系数的乘积,容量就会自动翻倍
HashSet类可以用来存储不重复的元素。考虑到效率的因素,添加到散列集中的对象必须以一种正确分布散列码的方式来实现hashCode方法。hashCode方法在Object类中定义。如果两个对象相等,那么这两个对象的散列码必须一样。两个不相等的对象可能会有相同的散列码,因此你应该实现 hashCode 方法以避免出现太多这样的情况。
LinkedHashSet
LinkedHashSet 用一个链表实现来扩展HashSet类,它支持规则集内的元素顺序。HashSet中的元素是没有顺序的,而LinkedHashSet中的元素可以按照它们插人规则集的顺序获取。
LinkedHashSet 保持了元素插人时的顺序。要强加一个不同的顺序(例如,升序或降序),可以使用TreeSet类
TreeSet
如图,SortedSet 是Set 的一个子接口,它可以确保规则集中的元素是有序的。另外,它还提供方法 first()和last()以返回规则集中的第一个元素和最后一个元素,以及方法headSet(toElement) 和 tailSet(fromElement)以分别返回规则集中元素小于toElement 和大于或等于 fromElement 的那一部分。
Tip
当更新一个规则集时,如果不需要保持元素的排序关系,就应该使用散列集,因为在散列集中插入和删除元素所花的时间较少。当需要一个排序的规则集时,可以从这个散列集创建一个树形集。
比较规则集和线性表的性能
- 在无重复元素进行排序方面,规则集比线性表更加高效。线性表在通过索引来访问元素方面非常有用。
- 测试一个元素是否在一个散列集中比测试它是否在一个线性表中要快得多。
Map
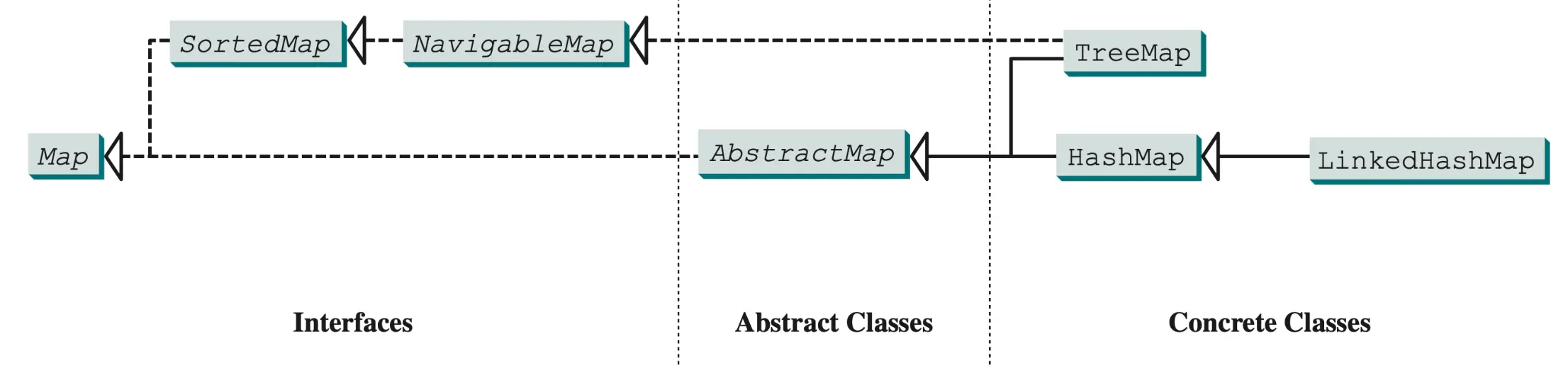


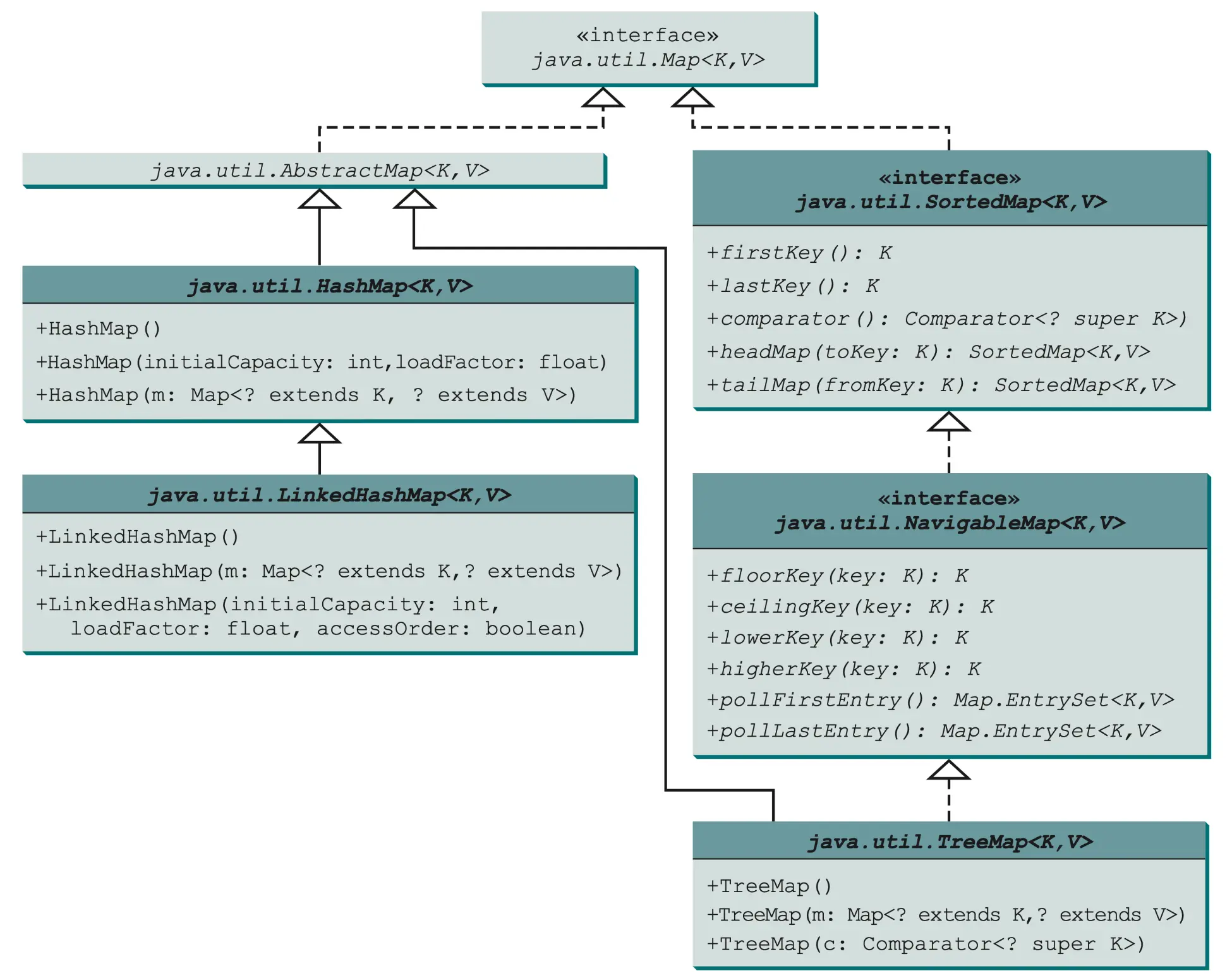
- LinkedHashMap 类用链表实现来扩展 HashMap 类,它支持映射中条目的排序。
- 在LinkedHashMap 中,元素既可以按照它们插人映射的顺序排序,也可以按它们被最后一次访同时的顺序,从最早到最晚排序。无参构造方法是以插入顺序来创建LinkedHashMap 的。要按访问顺序创建 LinkedHashMap 对象,可以使用构造方法LinkedHashMap (initialCapacity, loadFactor,true)。
- TreeMap类在遍历排好顺序的键时是很高效的。键可以使用Comparable 接口或Comparator 接口来排序。
import java.util.*;
public class TestMap {
public static void main(String[] args) {
// 创建一个 HashMap
Map<String, Integer> hashMap = new HashMap<>();
hashMap.put("Smith", 30);
hashMap.put("Anderson", 31);
hashMap.put("Lewis", 29);
hashMap.put("Cook", 29);
System.out.println("Display entries in HashMap");
System.out.println(hashMap + "\n");
// 从前面的 HashMap 创建一个 TreeMap
Map<String, Integer> treeMap = new TreeMap<>(hashMap);
System.out.println("Display entries in ascending order of key");
System.out.println(treeMap);
// 创建一个 LinkedHashMap
Map<String, Integer> linkedHashMap = new LinkedHashMap<>(16, 0.75f, true);
linkedHashMap.put("Smith", 30);
linkedHashMap.put("Anderson", 31);
linkedHashMap.put("Lewis", 29);
linkedHashMap.put("Cook", 29);
// 显示 Lewis 的年龄
System.out.println("\nThe age for " + "Lewis is " + linkedHashMap.get("Lewis"));
System.out.println("Display entries in LinkedHashMap");
System.out.println(linkedHashMap);
// 显示每个条目(姓名和年龄)
System.out.print("\nNames and ages are ");
treeMap.forEach((name, age) -> System.out.print(name + ": " + age + " "));
}
}Display entries in HashMap
{Lewis=29, Smith=30, Cook=29, Anderson=31}
Display entries in ascending order of key
{Anderson=31, Cook=29, Lewis=29, Smith=30}
The age for Lewis is 29
Display entries in LinkedHashMap
{Smith=30, Anderson=31, Cook=29, Lewis=29}
Names and ages are Anderson: 31 Cook: 29 Lewis: 29 Smith: 30 HashMap 中条目的顺序是随机的,而 TreeMap 中的条目是按键的升序排列的LinkedHashMap 中的条目则是按元素最后一次被访问的时间从最早到最晚排序的。
Tip
如果更新映射时不需要保持映射中元素的顺序,就使用 HashMap;如果需要保持映射中元素的插入顺序或访问顺序,就使用LinkedHashMap;如果需要使映射按照键排序,就使用 TreeMap。
Map 如何与集合框架集成?
虽然 Map 不是 Collection,但它提供了转换为 Collection 的方法:
1. 三种视图
Map<String, Integer> map = new HashMap<>();
map.put("Alice", 25);
map.put("Bob", 30);
// 1. 键的集合(Set)
Set<String> keys = map.keySet();
// keys = ["Alice", "Bob"]
// 2. 值的集合(Collection)
Collection<Integer> values = map.values();
// values = [25, 30]
// 3. 键值对的集合(Set of Map.Entry)
Set<Map.Entry<String, Integer>> entries = map.entrySet();
// entries = [Alice=25, Bob=30]2. 实际应用示例
// 遍历 Map 的不同方式
Map<String, String> phoneBook = new HashMap<>();
phoneBook.put("Alice", "123-456");
phoneBook.put("Bob", "789-012");
// 方式1:遍历键
for (String name : phoneBook.keySet()) {
System.out.println(name + ": " + phoneBook.get(name));
}
// 方式2:遍历值
for (String number : phoneBook.values()) {
System.out.println("Number: " + number);
}
// 方式3:遍历键值对(最高效)
for (Map.Entry<String, String> entry : phoneBook.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}