该文章参考于: 点击链接
DETRs Beat YOLOs on Real-time Object Detection
本文提出实时检测 Transformer(RT-DETR),它是首个实时端到端目标检测器。针对 YOLO 系列受 NMS 影响速度和精度、DETRs 计算成本高的问题,RT-DETR 通过设计高效混合编码器解耦特征交互与融合提升速度,提出不确定性最小化查询选择优化初始查询提高精度,且能通过调整解码器层数灵活调优速度。
研究背景
实时目标检测应用广泛,现有基于 CNN 的实时检测器如 YOLO 系列,因合理权衡速度和精度而受欢迎,但需非极大值抑制(NMS)后处理,影响速度和精度,且 NMS 超参数难选。基于 Transformer 的端到端检测器(DETRs)虽有优势,但计算成本高,无法满足实时检测要求。
相关工作
- 实时目标检测器:YOLOv1 是首个基于 CNN 的单阶段实时目标检测器,发展出基于锚和无锚两类,在速度和精度上取得平衡,广泛应用,但后处理需 NMS。
- 端到端目标检测器:DETR 消除手工组件,采用二分匹配预测目标集,但存在训练收敛慢、计算成本高和查询难优化等问题,有多种改进变体从加速收敛、降低计算成本和优化查询初始化等方面改进。
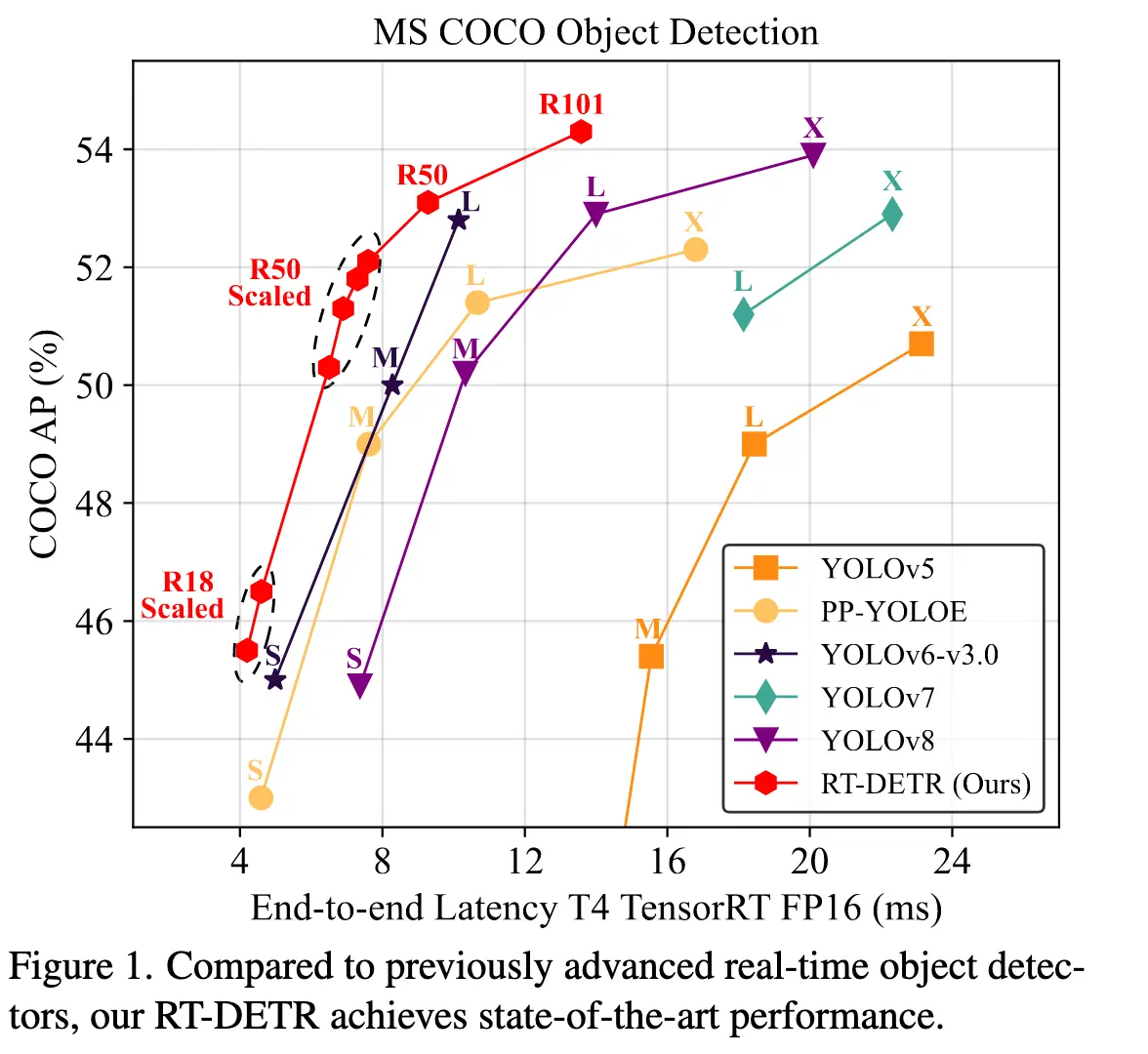
效果
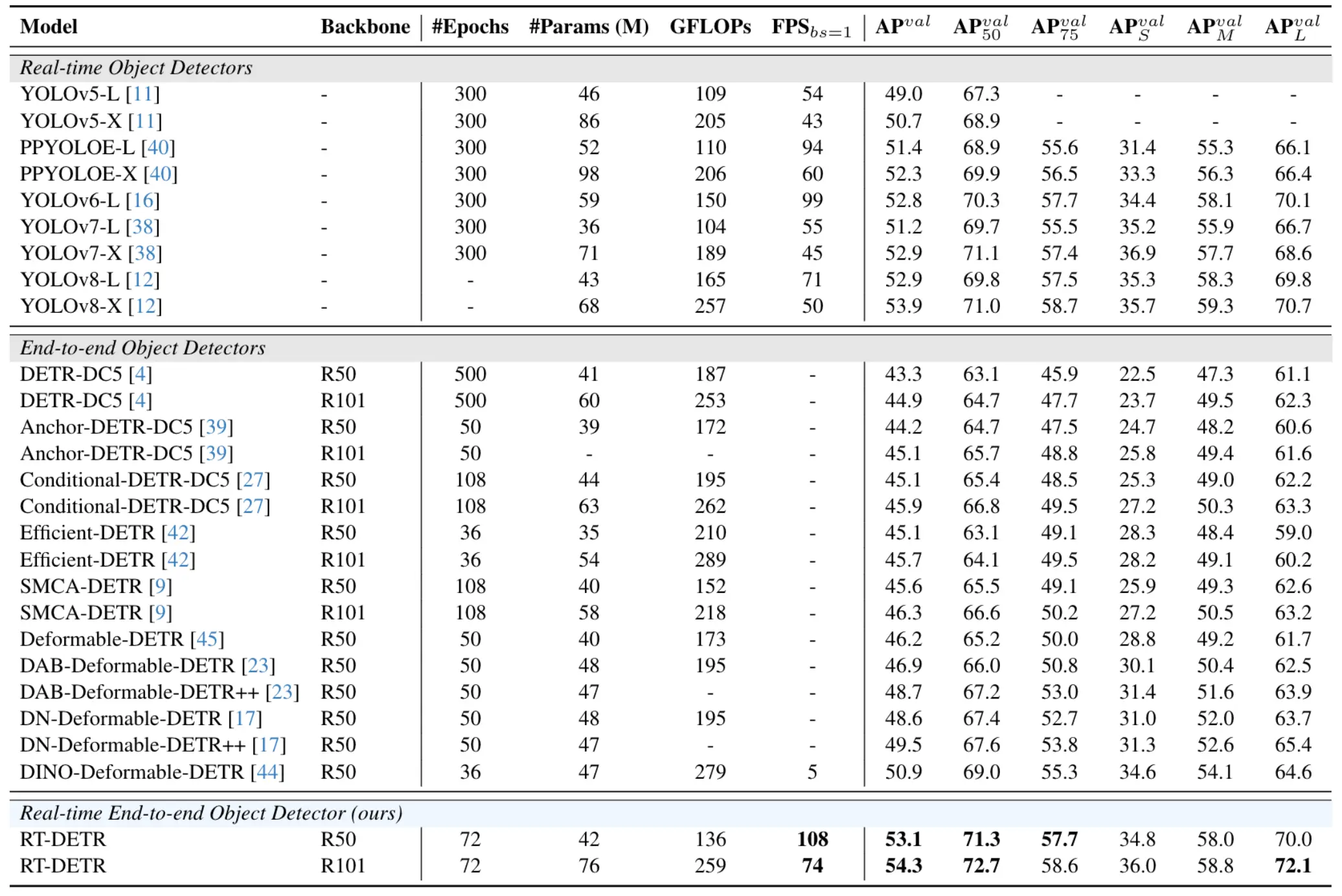
与以前先进的实时目标探测器相比,RT-DETR实现了最先进的性能。
模型设计
-
模型概述:RT-DETR 由骨干网络、高效混合编码器和带辅助预测头的 Transformer 解码器组成。骨干网络最后三层特征输入编码器,经处理后由不确定性最小化查询选择为解码器提供初始对象查询,解码器生成类别和边界框。
-
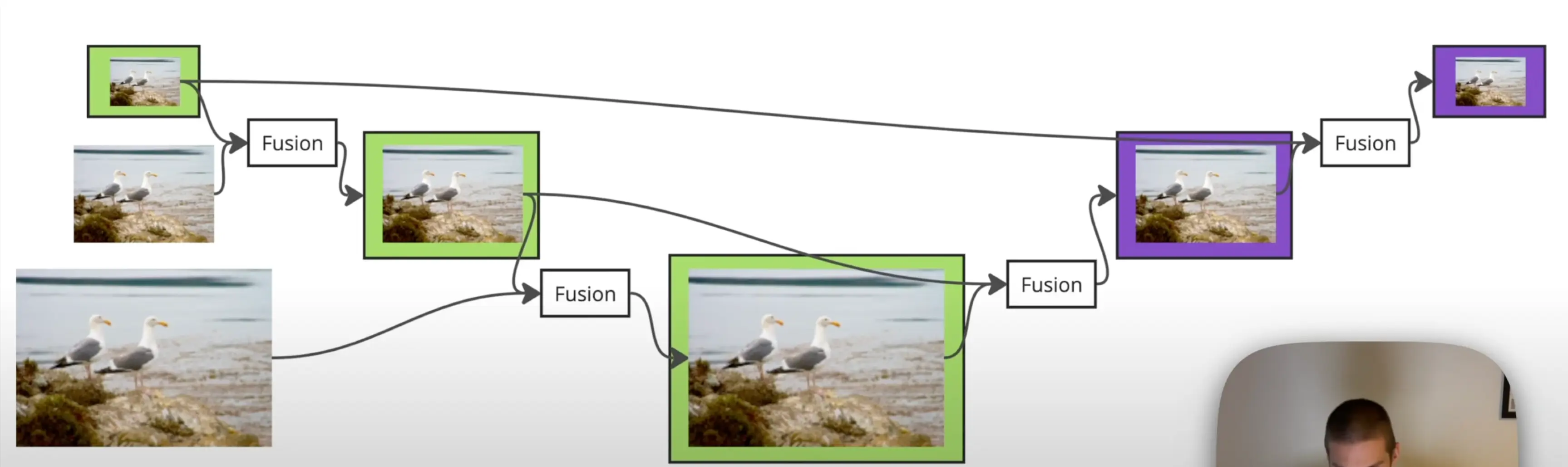
高效混合编码器:多尺度特征使编码器成计算瓶颈,设计不同变体分析计算冗余。提出的高效混合编码器含基于注意力的尺度内特征交互(AIFI)和基于 CNN 的跨尺度特征融合(CCFF)模块。AIFI 对高层特征进行尺度内交互,降低计算成本;CCFF 优化跨尺度融合,提升效率。
-
不确定性最小化查询选择:现有查询选择用置信度分数选特征,忽略定位信息,导致特征不确定性高。提出的方案通过构建和优化认知不确定性,为解码器提供高质量查询,提升检测精度。
网络结构
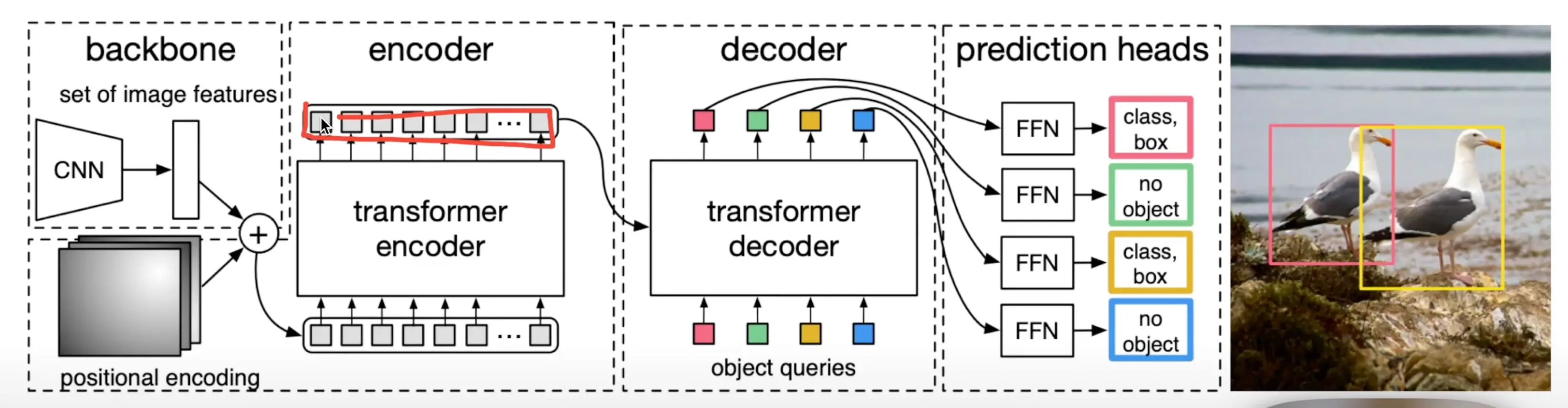
进入transformer encoder之前进行了展平操作,会丢失位置信息,故进行了位置编码,然后再使用transformer操作
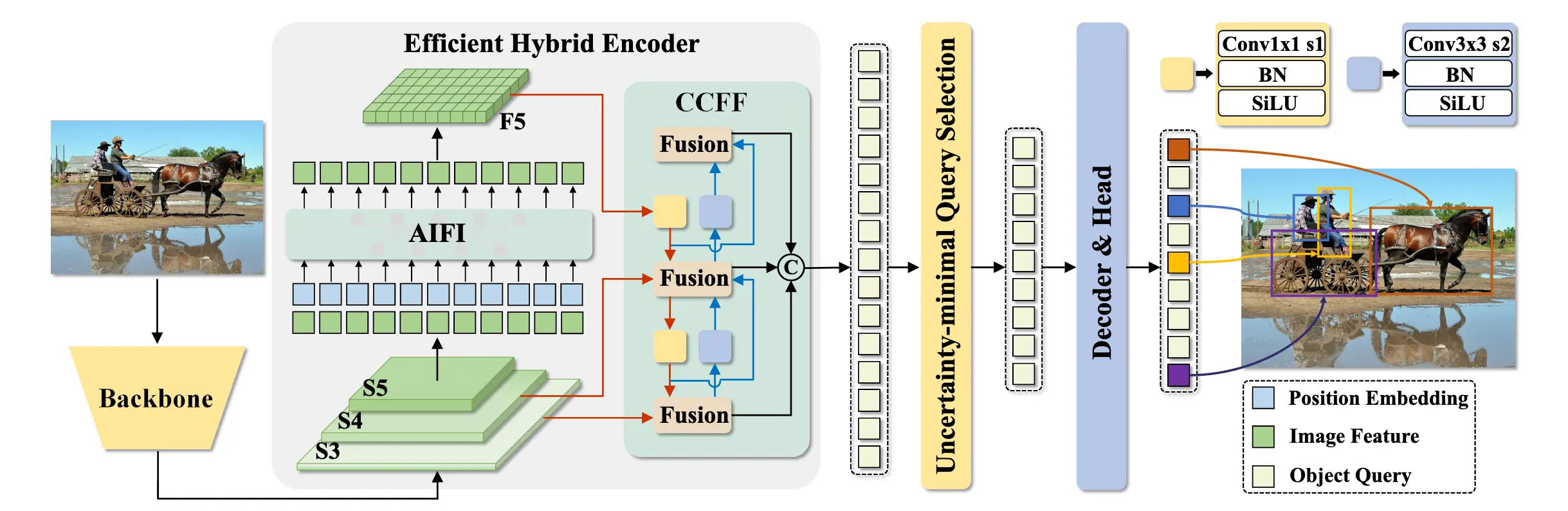
自注意力机制,每个像素都与其他像素进行交互(只对最小分辨率应用)

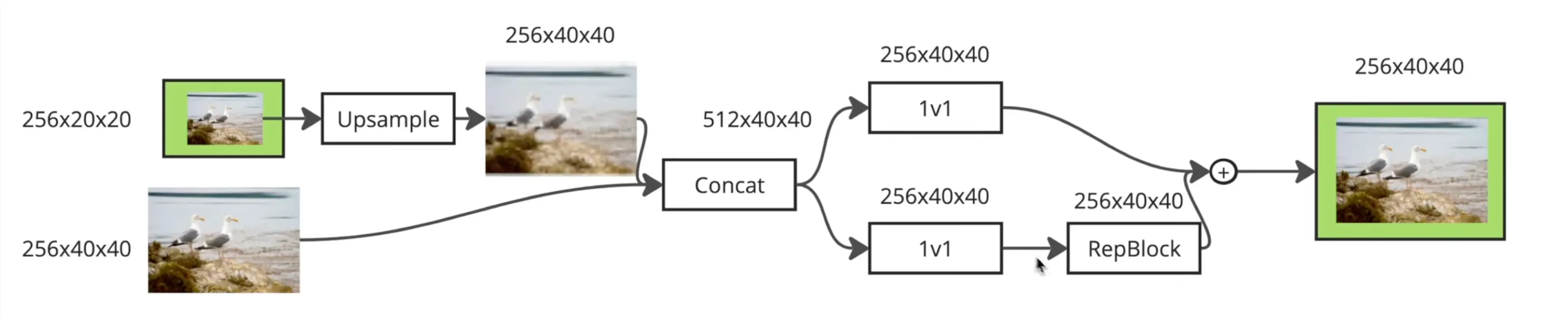
上采样
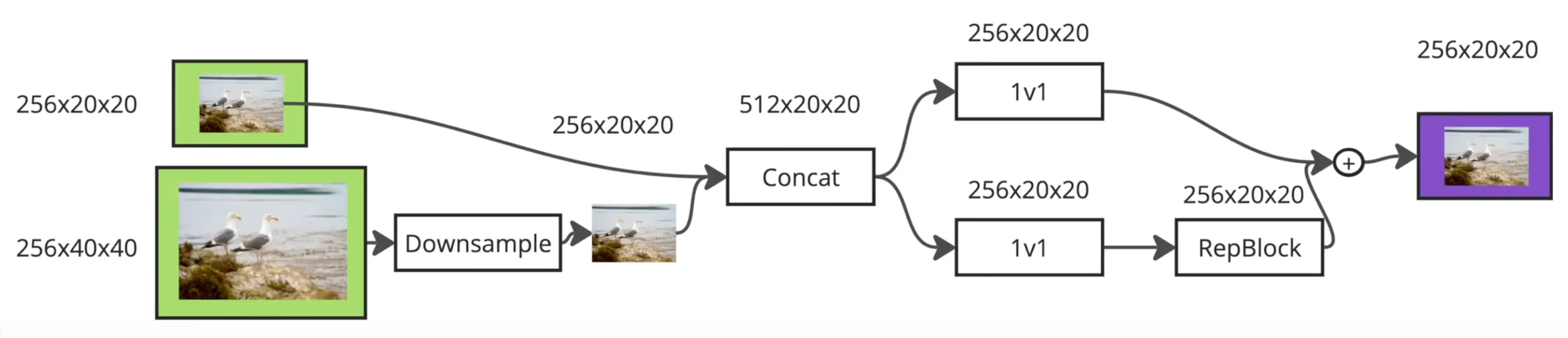
下采样
与最先进模型的对比(仅对比 YOLO 检测器的 L 和 X 模型)。RT-DETR 在速度和精度上均优于最先进的 YOLO 检测器和 DETR 模型。
FPN和PAN
- FPN (自顶向下路径) :
- FPN 首先通过一个自顶向下的路径,将高层(语义信息强但分辨率低)的特征图通过上采样,并与来自骨干网络较低层(分辨率高但语义信息弱)的特征图进行横向连接和融合。这样可以为低层特征补充丰富的语义信息。
- PAN (自底向上路径) :
- 在FPN之后,PAN引入了一个额外的自底向上的路径。
- 这条路径从FPN输出的最低层(分辨率最高)特征图开始,逐步向上(向分辨率更低的特征图)聚合信息。
- 目的 :FPN的自顶向下路径有效地将语义信息传递到较低层,但从骨干网络的顶层到底层,信息传递的路径可能较长。PAN通过增加一条从低层到高层的短路径,可以更好地保留和传递低层特征中的精确定位信息(例如边缘、角点等)。这有助于更准确地定位目标。
PAN路径通过自底向上的方式,将FPN输出的具有丰富语义信息的特征图与更低层级的精确定位信息进行有效聚合,进一步增强了多尺度特征的表达能力,特别是对于小物体的检测和精确定位是有益的。
整个流程可以概括为:
骨干网络 → 输入投影 → (可选Transformer编码) → FPN (自顶向下增强) → PAN (自底向上增强) → 输出特征
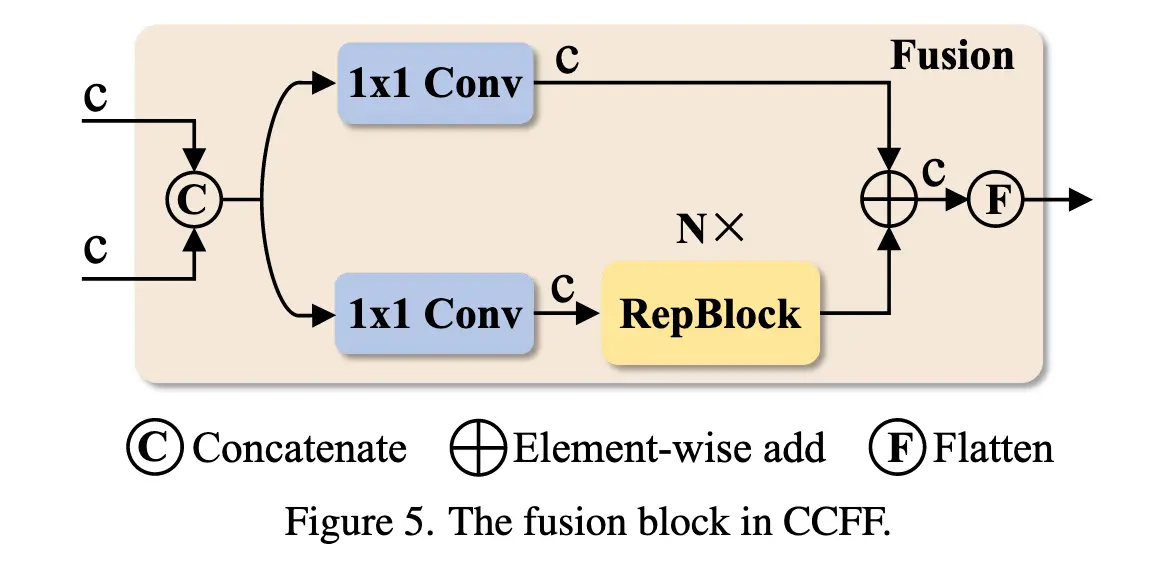
CSPRepLayer
CSPRepLayer 是一个结合了 CSPNet (Cross Stage Partial Network) 和 RepVGG 思想的神经网络模块。它的主要目的是在保持或提升特征表达能力的同时,优化计算效率和参数量。
// ... existing code ...
class CSPRepLayer(nn.Module):
'''CSPRepLayer 结合了 CSPNet (Cross Stage Partial Network) 和 RepVGG 的思想。
它将输入特征分成两部分,一部分通过一系列RepVggBlock处理,另一部分直接通过一个卷积层,
最后将两部分的结果融合。
'''
def __init__(self,
in_channels,
out_channels,
num_blocks=3, # RepVggBlock的数量
expansion=1.0, # 中间隐藏通道的扩展因子
bias=None, # 卷积层是否使用偏置
act="silu"): # 激活函数类型
super(CSPRepLayer, self).__init__()
hidden_channels = int(out_channels * expansion)
# 第一个1x1卷积,用于处理输入特征的一部分
self.conv1 = ConvNormLayer(in_channels, hidden_channels, 1, 1, bias=bias, act=act)
# 第二个1x1卷积,用于处理输入特征的另一部分
self.conv2 = ConvNormLayer(in_channels, hidden_channels, 1, 1, bias=bias, act=act)
# 一系列RepVggBlock
self.bottlenecks = nn.Sequential(*[
RepVggBlock(hidden_channels, hidden_channels, act=act) for _ in range(num_blocks)
])
# 如果最终输出通道与隐藏通道不同,则添加一个1x1卷积进行调整
if hidden_channels != out_channels:
self.conv3 = ConvNormLayer(hidden_channels, out_channels, 1, 1, bias=bias, act=act)
else:
self.conv3 = nn.Identity()
def forward(self, x):
# 输入特征x通过conv1,然后通过一系列bottlenecks (RepVggBlocks)
x_1 = self.conv1(x)
x_1 = self.bottlenecks(x_1)
# 输入特征x通过conv2
x_2 = self.conv2(x)
# 将两部分的输出相加,然后通过conv3(如果存在)
return self.conv3(x_1 + x_2)
// ... existing code ...CSPNet (Cross Stage Partial Network) 思想 :
- CSPRepLayer 采用了 CSPNet 的核心思想,即将输入特征图在通道维度上分成两部分(或者说,对原始输入进行两次独立的初始变换)。
- 第一部分 : 输入 x 经过 self.conv1 (一个1x1卷积) 变换后,再通过一系列的 RepVggBlock ( self.bottlenecks ) 进行深度特征提取。这构成了网络的主干计算路径。
- 第二部分 : 输入 x 经过 self.conv2 (另一个1x1卷积) 进行简单的变换。这部分特征通常被称为“残差部分”或“旁路部分”,它保留了部分原始信息,并减少了主干路径的计算量。
RepVGG 思想 :
- 在主干计算路径中, CSPRepLayer 使用了 RepVggBlock 。
- RepVggBlock 的特点是:
- 训练时 : 包含多个分支(通常是一个3x3卷积分支和一个1x1卷积分支,有时还有一个恒等映射分支)。这些分支的输出会相加。
- 推理/部署时 : 这些多分支结构可以通过代数等价转换为一个单一的3x3卷积层。这种转换称为“结构重参数化”,可以在不损失精度的情况下显著提高推理速度并减少参数量。
特征融合 :
- 经过 self.bottlenecks 处理的第一部分特征 ( x_1 ) 和经过 self.conv2 处理的第二部分特征 ( x_2 ) 会被 相加 ( x_1 + x_2 )。
- 这种融合方式结合了深度提取的复杂特征和相对浅层的特征。
输出调整 :
- 融合后的特征会经过 self.conv3 。
- 如果 hidden_channels (内部处理的通道数) 与期望的 out_channels (输出通道数) 不同, self.conv3 会是一个1x1卷积,用于调整通道数并进一步融合特征。
- 如果两者相同, self.conv3 则是一个 nn.Identity() 模块,即不进行任何操作。
优势:
- 效率 : CSPNet 的部分连接策略减少了计算冗余。RepVGG 的结构重参数化特性使得推理时模型更轻更快。
- 性能 : 结合了不同路径的特征,有助于学习更丰富的特征表示。
- 灵活性 : 可以通过调整 num_blocks 和 expansion 等参数来控制模型的容量和复杂度。