发布探店笔记
笔记介绍
- 功能定位:网红用户通过图文结合的形式发布店铺体验,为商家进行营销推广
- 内容组成:
- 图片:展示店铺环境、菜品等(通常先拍照后食用)
- 文字:搭配诗意文案(如”生活不仅要有眼前的苟且,还要有诗和远方”)
- 商业本质:属于营销广告形式,实际体验可能与描述存在差异
功能实现
- 前端流程:
- 点击底部”+“按钮进入发布页
- 依次上传图片、填写标题、输入内容、选择关联商户
- 点击发布按钮提交
- 技术特点:
- 图片上传与笔记发布为独立接口
- 图片先上传至nginx服务器(路径:
C:\develop\idea-space\hm-dianping-web\imgs\) - 发布时提交的是图片URL而非文件本身
相关接口
- uploadBlog接口
- 核心逻辑:
- 接收MultipartFile类型的图片文件
- 生成唯一文件名(防止重名冲突)
- 保存到nginx服务器的指定目录
- 返回图片访问URL
- 关键配置:
- 上传目录通过
SystemConstants.IMAGE_UPLOAD_DIR配置 - 实际开发中应使用文件服务器,演示简化使用本地存储
- 上传目录通过
- 核心逻辑:
Warning
需要自行调整
SystemConstants下IMAGE_UPLOAD_DIR变量的值为自己设备上前端项目下的imgs目录
@PostMapping("blog")
public Result uploadImage(@RequestParam("file") MultipartFile image) {
try {
// 获取原始文件名称
String originalFilename = image.getOriginalFilename();
// 生成新文件名
String fileName = createNewFileName(originalFilename);
// 保存文件
image.transferTo(new File(SystemConstants.IMAGE_UPLOAD_DIR, fileName));
// 返回结果
log.debug("文件上传成功,{}", fileName);
return Result.ok(fileName);
} catch (IOException e) {
throw new RuntimeException("文件上传失败", e);
}
}- APIBlog接口
- 处理流程:
- 从用户会话获取发布者ID
- 组合前端提交的标题、内容、图片URL、店铺ID
- 调用blogService.save()保存到数据库
- 返回新笔记的ID
- 数据验证:
- 必须字段:userId、shopId、title、images、content
- 自动填充:创建时间、点赞数、评论数
- 处理流程:
@PostMapping
public Result saveBlog(@RequestBody Blog blog) {
// 获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 保存探店博文
blogService.save(blog);
// 返回id
return Result.ok(blog.getId());
}查看探店笔记
public Result queryBlogById(Long id) {
Blog blog = getById(id);
if (blog == null) {
return Result.fail("笔记不存在!");
}
queryBlogUser(blog);
return Result.ok(blog);
}
/**
* 查询用户
*
* @param blog
*/
private void queryBlogUser(Blog blog) {
Long userId = blog.getUserId();
User user = userService.getById(userId);
blog.setName(user.getNickName());
blog.setIcon(user.getIcon());
}点赞
- 查询个人博客接口:
- 路径:/of/me
- 功能:获取当前登录用户的所有博客
- 实现步骤:
- 通过UserHolder.getUser()获取当前登录用户信息
- 使用blogService.query()构建查询条件,其中.eq(“user_id”, user.getId())限定只查询当前用户的博客
- 分页查询,默认每页显示SystemConstants.MAX_PAGE_SIZE条记录
- 返回当前页的博客记录列表
- 热门博客查询接口:
- 路径:
/hot - 功能:获取热门博客列表
- 特点:直接调用blogService.queryHotBlog(current)服务方法
- 路径:
- 博客详情查询接口:
- 路径:
/{id} - 功能:根据ID查询单篇博客详情
- 实现:调用blogService.queryBlogById(id)方法
- 路径:
- 博客点赞接口:
- 路径:
/like/{id} - 请求方式:PUT
- 实现原理:
- 直接执行SQL更新语句:
UPDATE tb_blog SET liked = liked + 1 WHERE id = ? - 使用MyBatis-Plus的链式调用:
blogService.update().setSql("liked = liked + 1").eq("id", id).update()
- 直接执行SQL更新语句:
- 注意点:该实现会直接操作数据库,每次点赞都会产生一次数据库更新
- 路径:
完善点赞功能
-
测试现象:用户可无限次点击点赞按钮,每次点击都会使点赞数+1
-
问题暴露:刷新页面后,被频繁点赞的笔记会跃升至排行榜第一名
-
逻辑缺陷:当前实现允许单个用户对同一笔记进行多次点赞,存在刷赞漏洞
-
请求机制:PUT请求直接修改数据库like字段(示例URL:http://localhost:8080/api/blog/like/4)
-
核心缺陷:后端未做用户校验,导致:
- 无点赞记录检查
- 无用户身份验证
- 直接执行累加操作
需求分析
- 业务规则:
- 唯一性原则:单个用户对同一笔记只能点赞一次
- 状态切换:二次点击应执行取消点赞操作
- 前端交互:
- 视觉反馈:点赞后按钮高亮显示(isLike=true),取消后恢复默认(isLike=false)
- 状态判断:通过blog类的isLike属性值决定按钮样式
- 实现要点:
- 后端校验:需记录用户点赞历史
- 数据同步:点赞状态需实时反映到前端界面
- 防刷机制:建立用户-笔记的点赞关系映射
实现原理
- 通过Redis的HASH结构存储点赞记录,键名为”blog:liked:文章ID”
- 用户ID作为字段名,实现用户维度的点赞状态记录
代码实现
- 将热门博客查询逻辑从控制器移至服务层,提升代码可维护性。
- 新增根据博客 ID 查询博客详情的接口,完善博客相关功能。
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
@TableName("tb_blog")
public class Blog implements Serializable {
/**
* 是否点赞过了
*/
@TableField(exist = false)
private Boolean isLike;
}private void isBlogliked(Blog blog) {
// 获取登录用户id
Long userId = UserHolder.getUser().getId();
// 判断当前用户是否已经点赞
String key = "blog:liked:" + blog.getId();
Boolean isLiked = stringRedisTemplate.opsForSet().isMember(key, userId.toString());
blog.setIsLike(BooleanUtil.isTrue(isLiked));
}public Result queryBlogById(Long id) {
Blog blog = getById(id);
if (blog == null) {
return Result.fail("笔记不存在!");
}
queryBlogUser(blog);
// 查询笔记是否被点赞
isBlogliked(blog);
return Result.ok(blog);
}public Result queryHotBlog(Integer current) {
// 根据用户查询
Page<Blog> page = query()
.orderByDesc("liked")
.page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页数据
List<Blog> records = page.getRecords();
// 查询用户
records.forEach(blog -> {
this.queryBlogUser(blog);
this.isBlogliked(blog);
});
return Result.ok(records);
}点赞排行榜
- 核心需求:按照点赞时间先后排序,返回Top5的用户
- 数据结构选择标准:
- 需要支持排序功能
- 需要保证用户唯一性
- 需要高效查找元素是否存在
集合对比
- List集合:
- 排序方式:按添加顺序排序(可通过lpush/rpush控制正序/倒序)
- 唯一性:不保证元素唯一
- 查找方式:按索引或首尾查找,效率低(需要遍历)
- Set集合:
- 排序方式:无法排序
- 唯一性:保证元素唯一(基于哈希表实现)
- 查找方式:根据元素直接查找(高效)
- SortedSet集合:
- 排序方式:根据score值排序(可自定义score如时间戳)
- 唯一性:保证元素唯一
- 查找方式:根据元素直接查找(高效)
SortedSet实现点赞业务
命令差异
- 添加元素:使用ZADD命令(与Set的SADD类似)
- 判断存在:
- Set使用SISMEMBER直接判断
- SortedSet使用ZSCORE间接判断(返回nil表示不存在)
- 原理:通过获取元素分数,非空返回值表示存在
原有业务代码调整
使用zset数据结构
private void isBlogliked(Blog blog) {
// 获取登录用户
UserDTO user = UserHolder.getUser();
if (user == null) {
// 用户未登录,无需查询是否点赞
return;
}
Long userId = user.getId();
// 判断当前用户是否已经点赞
String key = RedisConstants.BLOG_LIKED_KEY + blog.getId();
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
blog.setIsLike(score != null);
}public Result likeBlog(Long id) {
// 获取登录用户
Long userId = UserHolder.getUser().getId();
// 判断是否已经点赞
String key = RedisConstants.BLOG_LIKED_KEY + id;
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
if (score == null) {
// 未点赞
// 数据库点赞数+1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();
// 判断是否成功
if (isSuccess) {
// 保存用户到Redis
stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());
}
} else {
// 已点赞
// 数据库点赞数-1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();
if (isSuccess) {
// 删除用户
stringRedisTemplate.opsForZSet().remove(key, userId.toString());
}
}
return null;
}查询笔记点赞用户
-
为什么使用Redis ZSet存储点赞用户:
- ZSet是有序集合,可以按照时间顺序记录用户点赞的时间
- 使用
range(key, 0, 4)可以获取最早点赞的5个用户(也可以理解为top5) - 这样可以展示最先支持博客的用户
-
为什么需要保持顺序查询:
- Redis中的ZSet保存了用户点赞的时间顺序
- 通过
order by field(id, ...)语句可以确保查询出的用户列表保持与Redis中相同的顺序 - 这样前端显示的点赞用户列表就与用户点赞的先后顺序一致
-
为什么要使用ORDER BY FIELD
- 当从数据库查询这些用户信息时,如果不指定排序规则,数据库会按照默认的顺序(通常是主键顺序)返回结果,这会破坏Redis中保存的时间顺序。
ORDER BY FIELD(id, 101, 103, 102)会按照参数中指定的ID顺序返回记录,即先返回ID为101的用户,然后是103,最后是102。
FIELD函数说明
MySQL的
FIELD()函数接受一个值和一个值列表,返回该值在列表中的位置(从1开始),如果值不在列表中则返回0。例如:
FIELD('b', 'a', 'b', 'c')返回 2FIELD('d', 'a', 'b', 'c')返回 0在我们的场景中,
.last("order by field(id," + idStr + ")")会生成类似ORDER BY FIELD(id, 101, 103, 102)的SQL语句,确保查询结果按照指定的ID顺序返回。这样做的目的是确保前端显示的点赞用户列表与用户实际点赞的先后顺序一致,提供更好的用户体验。
public Result queryBlogLikes(Long id) {
// 查询top5的点赞用户
String key = RedisConstants.BLOG_LIKED_KEY + id;
Set<String> top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4);
if (top5 == null || top5.isEmpty()) {
return Result.ok(Collections.emptyList());
}
// 解析出用户id
List<Long> ids = top5.stream().map(Long::valueOf).collect(Collectors.toList());
String idStr = StrUtil.join(",", ids);
// 根据id查询用户
List<UserDTO> userDTOS = userService.query()
.in("id", ids).last("order by field(id," + idStr + ")").list()
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.ok(userDTOS);
}关注和取关
功能
- 功能定位:在探店图文详情页实现关注发布笔记作者的功能
- 接口设计:
- 关注接口路径:/follow/{id}/{isFollow}
- 查询接口路径:/follow/or/not/{id}
- 参数说明:
- id参数:表示要关注的用户ID
- isFollow参数:布尔值,true表示关注,false表示取关
- 状态查询:页面加载时会自动查询当前用户是否已关注作者
实现思路
- 数据关系:
- 使用中间表tb_follow记录用户关注关系
- 包含字段:自增主键id、用户ID(user_id)、被关注用户ID(follow_user_id)、创建时间
- 操作逻辑:
- 关注操作:向表中插入新记录
- 取关操作:删除对应记录(而非标记状态)
- 查询操作:根据两个用户ID查询记录是否存在
代码实现
/**
* 关注或取关
* @param followUserId
* @param isFollow
* @return
*/@Override
public Result follow(Long followUserId, Boolean isFollow) {
// 获取当前用户
Long userId = UserHolder.getUser().getId();
// 判断是关注还是取关
if (isFollow) {
// 关注
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
save(follow);
} else {
// 取关
remove(new QueryWrapper<Follow>()
.eq("user_id", userId)
.eq("follow_user_id", followUserId)
);
}
return Result.ok();
}
/**
* 判断是否关注
* @param followUserId
* @return
*/@Override
public Result isFollow(Long followUserId) {
Long userId = UserHolder.getUser().getId();
Integer count = query()
.eq("user_id", userId)
.eq("follow_user_id", followUserId).count();
return Result.ok(count > 0);
}共同关注
导入代码
UserController下
/**
* 根据id查询用户
* @param userId
* @return
*/@GetMapping("/{id}")
public Result queryUserById(@PathVariable("id") Long userId){
// 查询详情
User user = userService.getById(userId);
if (user == null) {
return Result.ok();
}
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
// 返回
return Result.ok(userDTO);
}BlogController下
@GetMapping("/of/user")
public Result queryBlogByUserId(
@RequestParam(value = "current", defaultValue = "1") Integer current,
@RequestParam("id") Long id) {
// 根据用户查询
Page<Blog> page = blogService.query()
.eq("user_id", id).page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页数据
List<Blog> records = page.getRecords();
return Result.ok(records);
}原业务代码修改
public Result follow(Long followUserId, Boolean isFollow) {
// 获取当前用户
Long userId = UserHolder.getUser().getId();
String followKey = "follow:" + userId;
// 判断是关注还是取关
if (isFollow) {
// 关注
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
boolean isSuccess = save(follow);
if (isSuccess) {
// 把关注用户的id放入redis的set集合中
stringRedisTemplate.opsForSet().add(followKey, followUserId.toString());
}
} else {
// 取关
boolean isSuccess = remove(new QueryWrapper<Follow>()
.eq("user_id", userId)
.eq("follow_user_id", followUserId)
);
if (isSuccess) {
// 把关注用户的id从redis的set集合中移除
stringRedisTemplate.opsForSet().remove(followKey, followUserId.toString());
}
}
return Result.ok();
}代码实现
@Override
public Result followCommons(Long id) {
// 获取当前用户
Long userId = UserHolder.getUser().getId();
String key = "follow:" + userId;
// 获取当前用户和传入用户共同关注的人
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, "follow:" + id);
// 解析Id
if (intersect == null || intersect.isEmpty()) {
return Result.ok(Collections.emptyList());
}
List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());
List<Object> users = userService.listByIds(ids)
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.ok(users);
}关注推送
- 基本概念: Feed流直译为”投喂”,通过无限下拉刷新持续提供沉浸式体验
- 传统模式对比:
- 传统模式需要用户主动检索内容(如百度搜索)
- Feed流主动推送内容,减少用户查找和思考时间
- 潜在问题: 可能因过度推送导致用户沉迷,浪费原本想节省的时间
Feed流的模式
- Timeline模式:
- 排序方式: 按内容发布时间简单排序
- 应用场景: 常用于好友或关注关系(如微信朋友圈)
- 优点: 实现简单,信息全面
- 缺点: 信息噪音多,用户不一定感兴趣,效率低
- 智能排序模式:
- 排序方式: 使用算法屏蔽违规和不感兴趣内容
- 应用场景: 抖音、快手等短视频平台
- 优点: 用户粘度高,容易沉迷
- 缺点: 算法不精准会导致反感
实现方案
拉模式
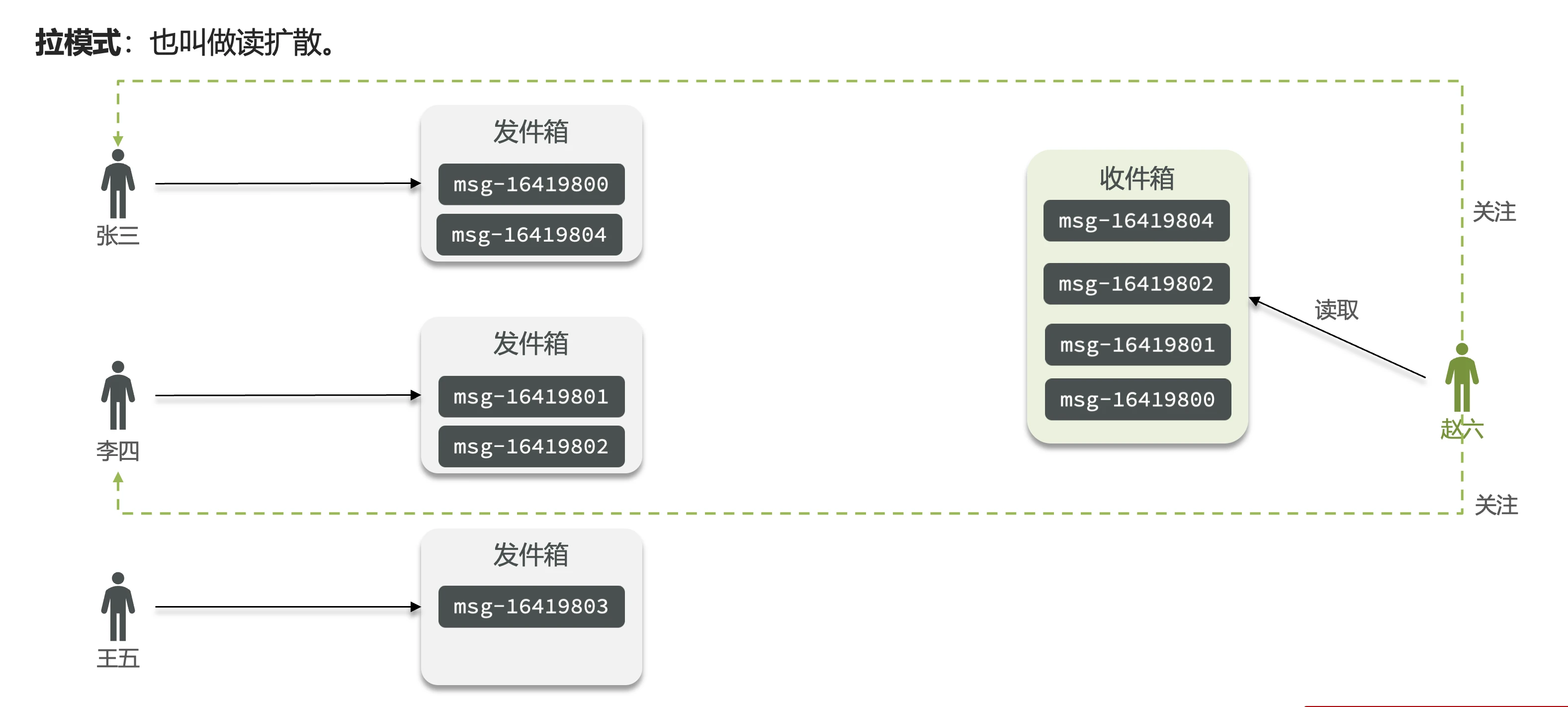
- 别名: 读扩散
- 工作原理:
- 每个内容发布者有独立发件箱存储消息(带时间戳)
- 粉丝读取时临时拉取关注者的发件箱内容并排序
- 优点: 节省内存空间(消息只存储一份)
- 缺点: 读取延迟高(特别是关注大量用户时)
- 适用场景: 很少单独使用
推模式
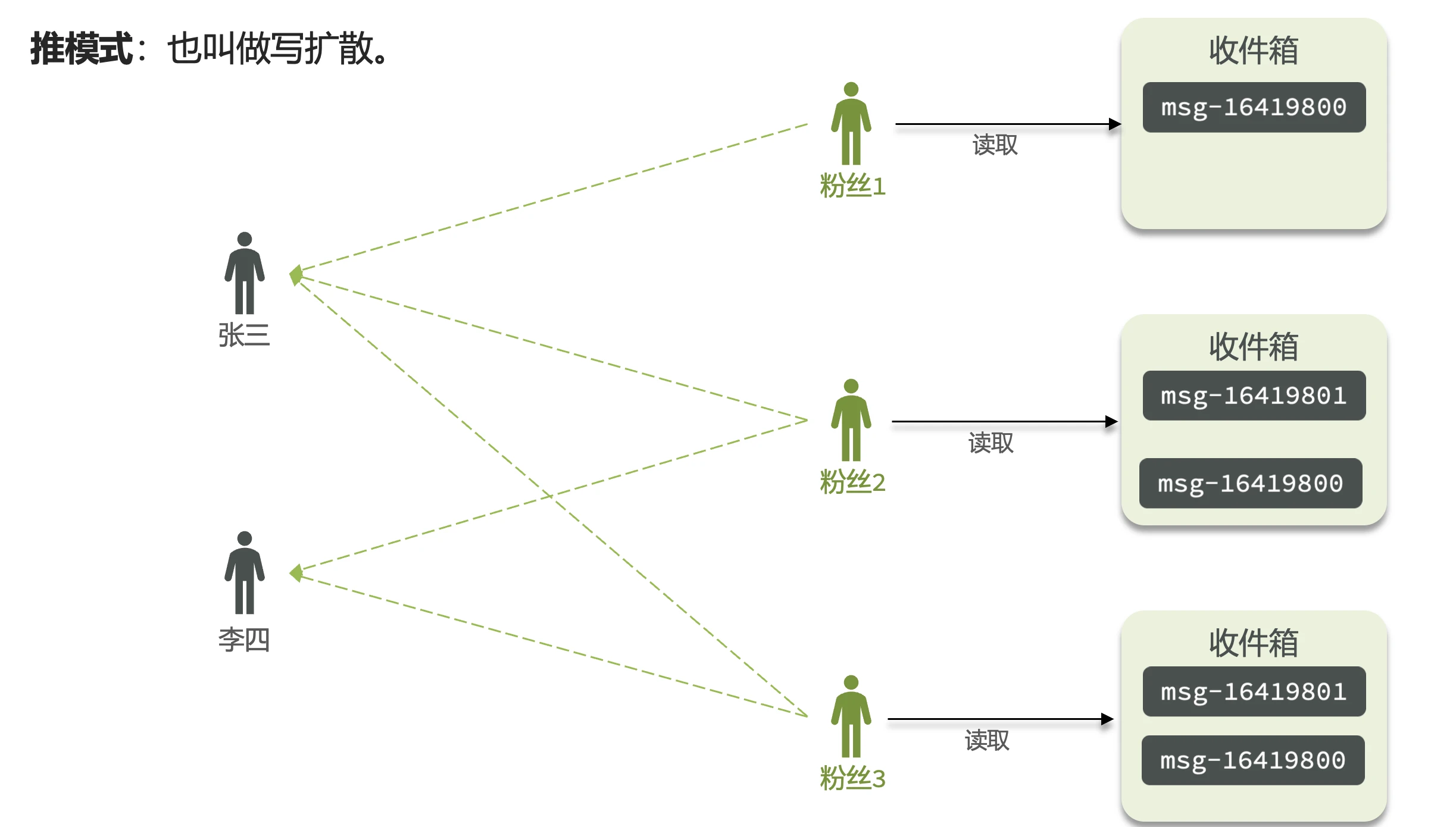
- 别名: 写扩散
- 工作原理:
- 发布者直接将消息推送给所有粉丝的收件箱
- 收件箱中消息已预先排序
- 优点: 读取延迟低,实现简单
- 缺点: 内存占用高(大V发消息需存储多份)
- 适用场景: 用户量少(千万以下)、无大V的平台
推拉结合模式
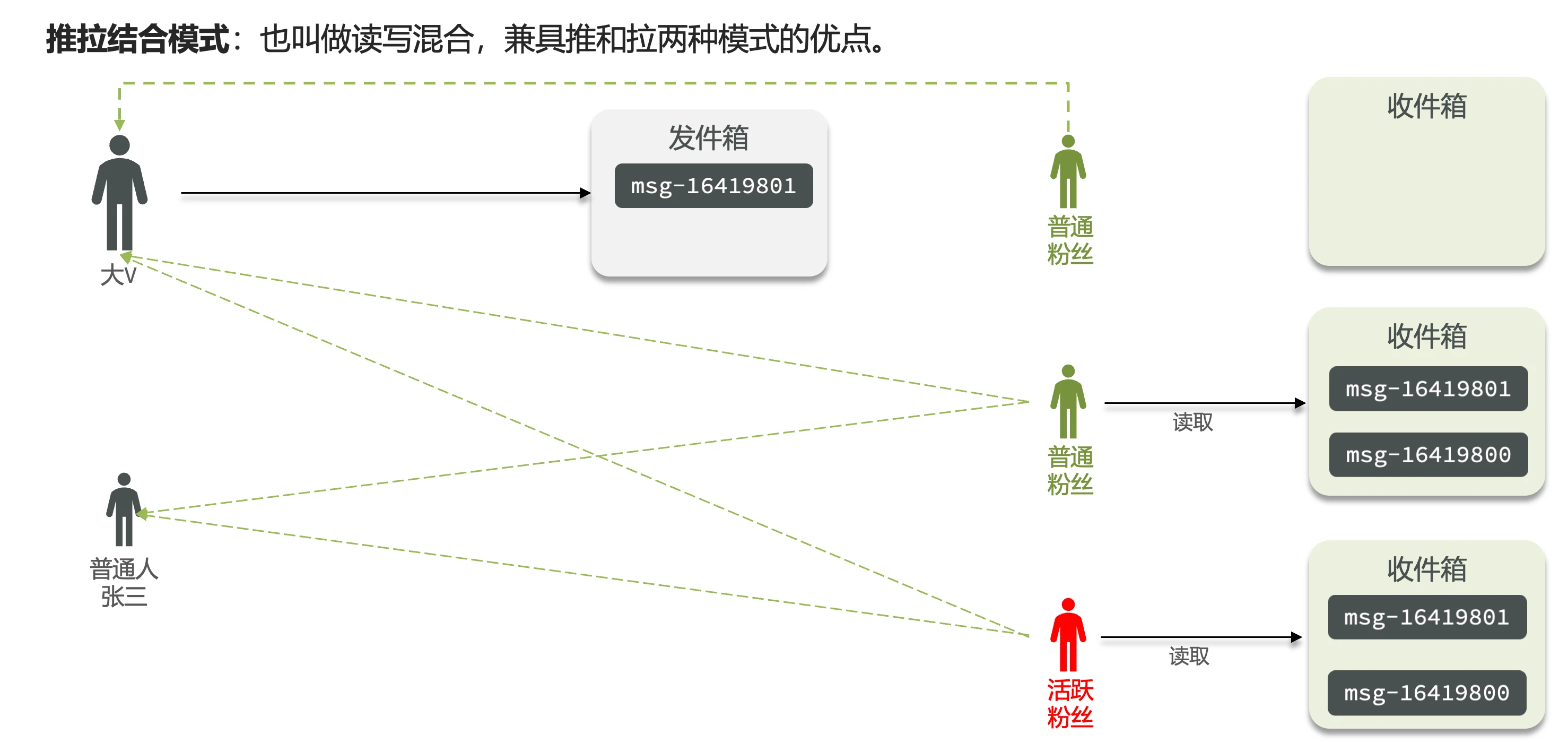
- 别名: 读写混合模式
- 工作原理:
- 对普通用户采用推模式(粉丝少)
- 对大V区分活跃/普通粉丝:
- 活跃粉丝:推模式(低延迟)
- 普通粉丝:拉模式(节省内存)
- 优点: 兼顾延迟和内存效率
- 缺点: 实现复杂
- 适用场景: 千万级用户量且存在大V的平台
总结
- 方案选择标准:
- 拉模式: 写比例低、读比例高、延迟高、实现复杂(不推荐)
- 推模式: 写比例高、读比例低、延迟低、实现简单(适合中小平台)
- 推拉结合: 各项指标居中、实现很复杂(适合大型平台)
- 项目选择: 本项目采用推模式,因用户量不大且无大V,在延迟和内存间取得较好平衡
推送到粉丝收件箱
- 核心需求:
- 修改新增探店笔记业务,保存blog到数据库的同时推送到粉丝收件箱
- 收件箱需支持按时间戳排序,必须使用Redis数据结构实现
- 查询收件箱数据时需支持分页查询
- 实现方案:
- 采用推模式实现关注推送功能
- 不维护发件箱,用户发布笔记时直接推送到所有粉丝收件箱
- 推送时仅保存笔记ID而非完整内容,节省内存空间
分页问题
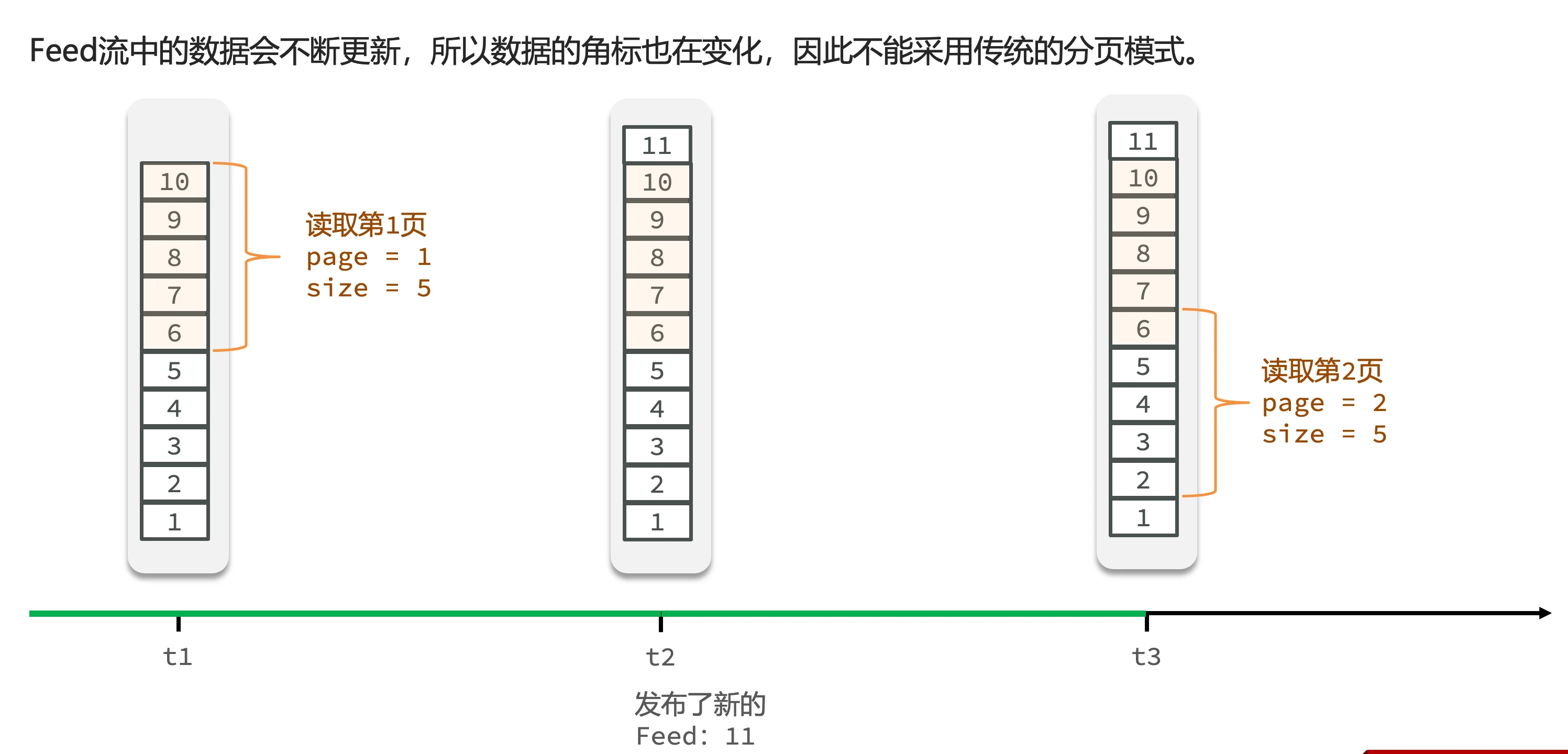
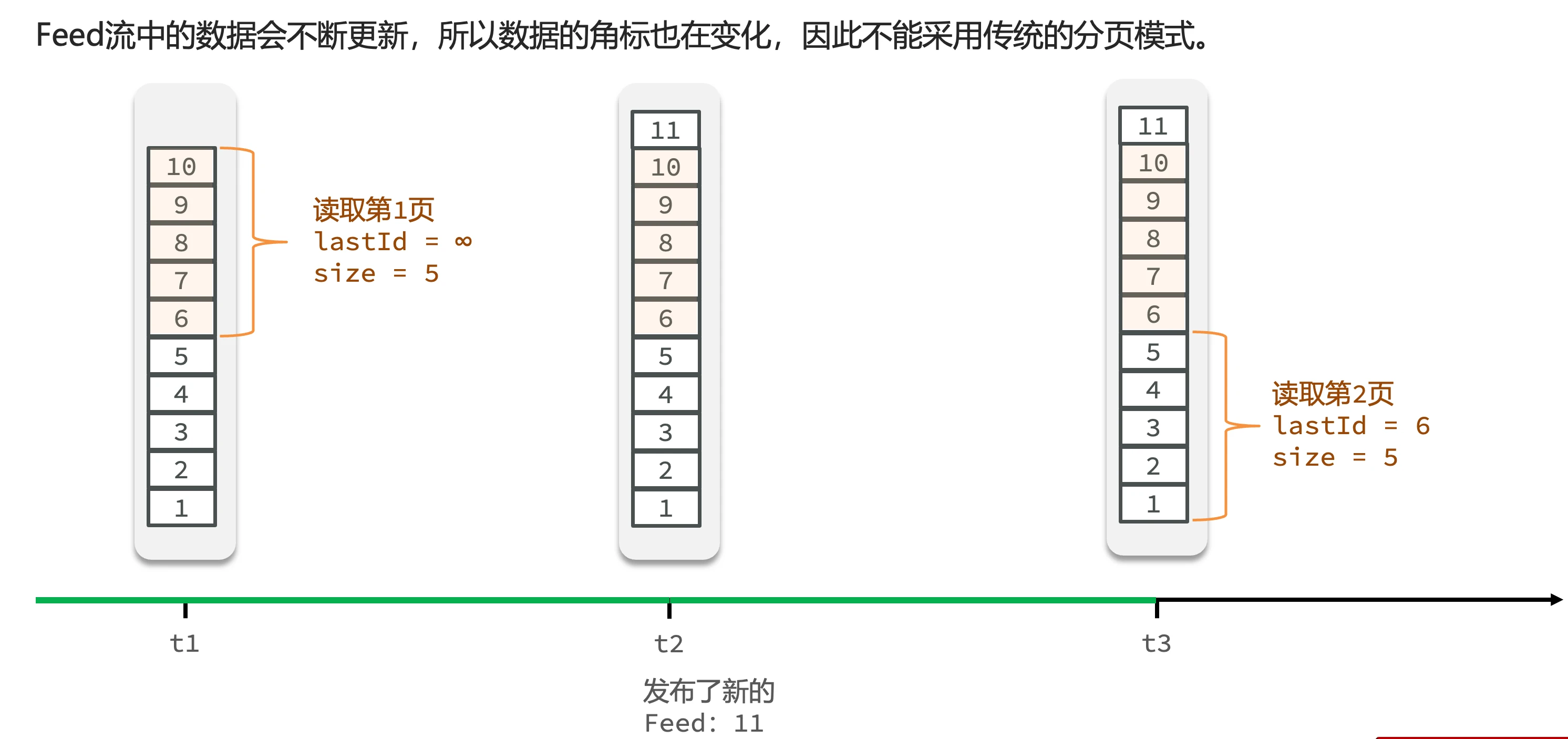
- 传统分页的缺陷:
- Feed流数据不断更新导致角标变化
- 示例:t1时刻查询第一页5条数据(6-10),t2时刻新增数据11导致原数据角标后移
- t3时刻查询第二页时会出现重复读取(再次获取6)
- 解决方案:
- 采用滚动分页模式
- 原理:记录每次查询的最后一条,下次从该位置继续查询
- 首次查询:设置起始ID为无穷大,按时间倒序获取
- 后续查询:使用上次查询的最小ID作为本次查询的起始点
- 数据结构选择:
- List和Sorted Set都能实现排序
- List仅支持角标查询,无法实现滚动分页
- Sorted Set支持按score范围查询,适合实现滚动分页
代码实现
用户发表笔记时将笔记id推送到粉丝收件箱
public Result saveBlog(Blog blog) {
// 获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 保存探店博文
boolean isSucess = save(blog);
if (!isSucess) {
return Result.fail("笔记保存失败!");
}
// 查询笔记作者的粉丝列表
List<Follow> fans = followService.query().eq("follow_user_id", user.getId()).list();
// 推送笔记id给所有粉丝
fans.forEach(fan -> {
// 获取粉丝id
Long userId = fan.getUserId();
String key = RedisConstants.FEED_KEY + userId;
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
});
// 返回id
return Result.ok(blog.getId());
}滚动分页查询收件箱
回顾
- 数据准备:示例中创建了包含6个元素的sorted set(z1),元素名称为m1-m6,分数值为1-6,模拟时间戳数据
- 排序规则:分数值越大代表数据越新,默认按分数降序排列
滚动分页查询参数
- 核心参数:
- max:当前时间戳(第一次查询)或上一次查询的最小分数(后续查询)
- min:固定为0(时间戳最小值)
- offset:第一次为0,后续为与上一次最小分数相同的元素数量
- count:固定值(如3)
- 参数确定规则:
- 第一次查询:
- max = 当前时间戳
- offset = 0
- 后续查询:
- max = 上一次查询结果中的最小分数
- offset = 上一次结果中与最小分数相同的元素数量
- 第一次查询:
- 优势:不受新插入数据影响,保证分页结果准确性
请求方式
- 请求方式:GET请求
- 请求路径:/api/blog/of/follow
- 核心参数:
- lastId:实际为时间戳参数,表示上一次查询的最小时间戳(用作本次查询的最大值)
- offset:偏移量参数,表示与最小时间戳相同的元素数量(用于跳过重复值)
返回值
- 必需字段:
- 数据集合:当前页的Blog列表
List<Blog> - minTime:本次结果中的最小时间戳(作为下次查询的lastId)
- offset:本次结果中与minTime相同的元素数量(作为下次查询的offset)
- 数据集合:当前页的Blog列表
- 实现要点:
- 后台需分析查询结果,计算minTime和offset
- 前端存储这两个值用于下次请求
- 首次查询时offset默认为0,后续必须传递准确值
代码实现
com/hmdp/dto/ScrollResult.java下定义dto
- 类名:ScrollResult,用于封装滚动分页查询结果
- 注解:使用@Data注解自动生成getter/setter方法
- 泛型设计:
- 采用泛型设计,使类具有通用性
- 不仅适用于当前博客查询,未来其他滚动分页场景也可复用
- 核心属性:
List<T> list:查询结果集合- Long minTime:本次查询的最小时间戳(即下次查询的max参数)
- Integer offset:偏移量,记录与上次查询最小值相同的元素个数
@Data
public class ScrollResult {
private List<?> list;
private Long minTime;
private Integer offset;
}@GetMapping("/of/follow")
public Result queryBlogOfFollow(
@RequestParam("lastId") Long max,
@RequestParam(value = "offset", defaultValue = "0") Integer offset) {
return blogService.queryBlogOfFollow(max, offset);
}在Redis中,我们使用ZSet(有序集合)来实现滚动分页查询。这种分页方式不是传统的基于页码和每页数量的分页,而是基于上一次查询结果中的最小时间戳和偏移量来获取下一批数据。
让我逐步解释queryBlogOfFollow方法的实现逻辑:
-
首先获取当前登录用户的ID,并构建Redis中该用户的收件箱key(
feed:{userId}):Long userId = UserHolder.getUser().getId(); String key = RedisConstants.FEED_KEY + userId; -
使用
reverseRangeByScoreWithScores方法按分数从高到低查询数据:Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet() .reverseRangeByScoreWithScores(key, 0, max, offset, 2);0, max表示查询分数在0到max之间的元素- offset是偏移量,跳过的元素个数
2是查询的元素个数- 这里的max通常是从上一次查询结果中获得的最小时间戳
-
如果查询结果为空,则返回空结果:
if (typedTuples == null || typedTuples.isEmpty()) { return Result.ok(); } -
解析查询结果,提取博客ID和时间戳信息:
List<Long> ids = new ArrayList<>(typedTuples.size()); long minTime = 0; int os = 1; // 最小元素的个数 for (ZSetOperations.TypedTuple<String> tuple : typedTuples) { // 获取id ids.add(Long.valueOf(tuple.getValue())); // 获取分数(时间戳) long time = tuple.getScore().longValue(); if (time == minTime) { os++; } else { minTime = time; os = 1; } }- 收集所有博客ID到
ids列表中 - 记录最小时间戳minTime
- 计算具有相同最小时间戳的元素个数
os
- 收集所有博客ID到
-
根据ID查询博客信息,并封装作者和点赞信息:
String idStr = StrUtil.join(",", ids); List<Blog> blogs = query().in("id", ids).last("order by field(id," + idStr + ")").list(); blogs.forEach(blog -> { // 封装作者信息 this.queryBlogUser(blog); // 封装点赞信息 this.isBlogliked(blog); }); -
封装结果并返回:
ScrollResult scrollResult = new ScrollResult(); scrollResult.setList(blogs); scrollResult.setOffset(os); scrollResult.setMinTime(minTime); return Result.ok(scrollResult);
这种滚动分页的优势在于:
- 避免了传统分页在深度分页时的性能问题
- 能够处理数据动态变化的情况
- 通过时间戳作为游标,可以实现”查看更多”的功能
前端在调用时会传入上一次查询结果中的minTime作为max参数,以及offset参数来获取下一页数据。
完整代码如下:
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
// 获取当前用户
Long userId = UserHolder.getUser().getId();
// 查询收件箱
String key = RedisConstants.FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
if (typedTuples == null || typedTuples.isEmpty()) {
return Result.ok();
}
// 解析数据
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime = 0;
int os = 1; // 最小元素的个数
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) {
// 获取id
ids.add(Long.valueOf(tuple.getValue()));
// 获取分数(时间戳)
long time = tuple.getScore().longValue();
if (time == minTime) {
os++;
} else {
minTime = time;
os = 1;
}
}
// 根据id查询blog
String idStr = StrUtil.join(",", ids);
List<Blog> blogs = query().in("id", ids).last("order by field(id," + idStr + ")").list();
blogs.forEach(blog -> {
// 封装作者信息
this.queryBlogUser(blog);
// 封装点赞信息
this.isBlogliked(blog);
});
// 封装并返回
ScrollResult scrollResult = new ScrollResult();
scrollResult.setList(blogs);
scrollResult.setOffset(os);
scrollResult.setMinTime(minTime);
return Result.ok(scrollResult);
}