BitMap用法
传统方法存储签到信息
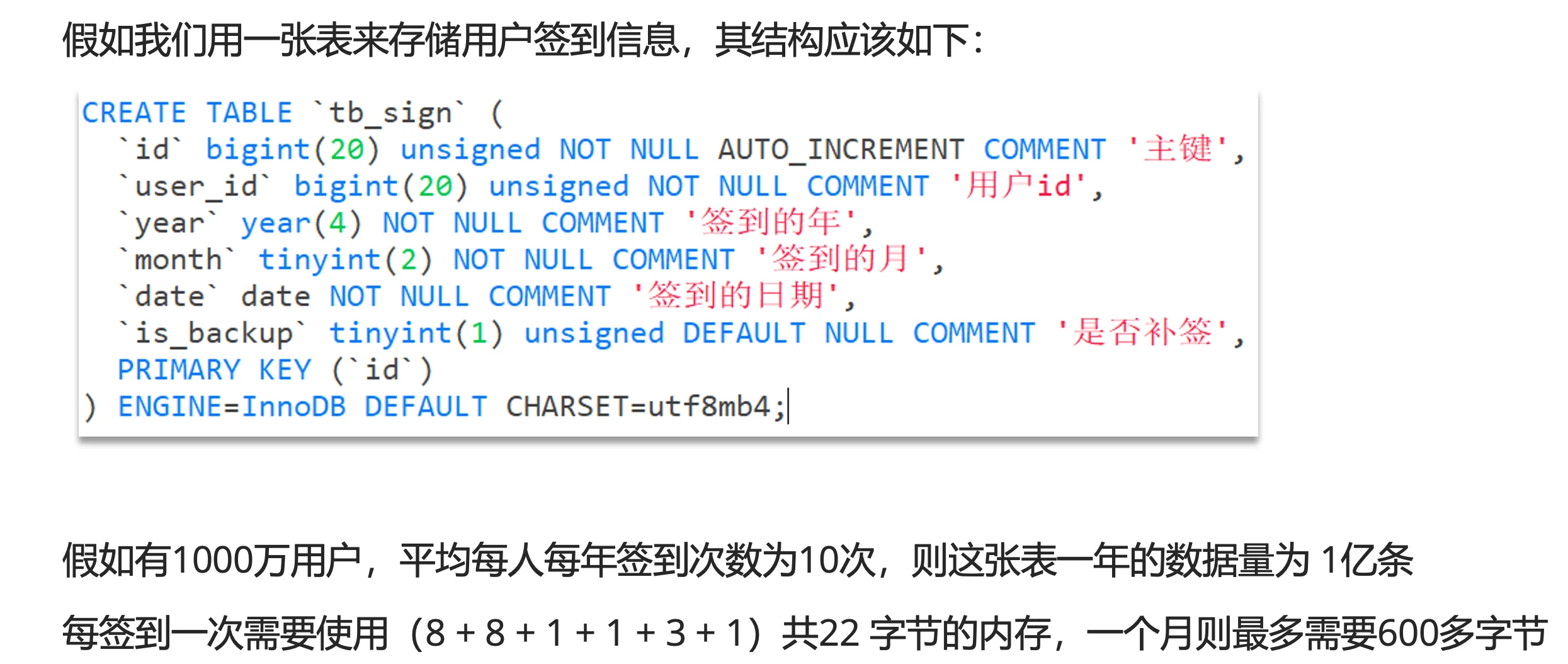
- 存储问题:传统数据库表存储方式(如tb_sign表)每个用户每天签到需要22字节,1000万用户每年约产生1亿条数据
- 字段说明:
- year/month:用于按月统计签到次数
- date:记录具体签到日期
- is_backup:标记是否为补签
- 空间消耗:一个月签到记录需600多字节,千万级用户时空间占用成为天文数字
签到卡

- 灵感来源:借鉴传统纸质签到卡形式,用二进制位表示签到状态
- 存储优化:一个月最多31天只需31bit(约4字节),相比传统方式节省数百倍空间
- 表示方法:1表示签到,0表示未签到,如”11100111”表示第1-3天和6-8天签到
操作命令
BitMap的操作命令有:
- SETBIT:向指定位置(offset)存入一个0或1
- GETBIT :获取指定位置(offset)的bit值
- BITCOUNT :统计BitMap中值为1的bit位的数量
- BITFIELD :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
- BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
- BITOP :将多个BitMap的结果做位运算(与 、或、异或)
- BITPOS :查找bit数组中指定范围内第一个0或1出现的位置
实现签到功能
Warning
因为Bitap底层是基于String数据结构,因此其操作也都封装在字符串相关操作中了。
public Result sign() {
// 获取当前登录用户
Long userId = UserHolder.getUser().getId();
// 获取日期
LocalDateTime now = LocalDateTime.now();
// 拼接key
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
String key = USER_SIGN_KEY + userId + keySuffix;
// 获取今天是本月的第几天
int day = now.getDayOfMonth();
// 写入redis
stringRedisTemplate.opsForValue().setBit(key, day - 1, true);
return Result.ok();
}连续签到天数
- 统计方法:从最后一次签到开始向前统计,直到遇到第一次未签到为止,累计的签到次数即为连续签到天数。
- 示例说明:给定签到记录”111000110110001011101111101111”,从最后一位”1”开始向前遍历,遇到第一个”0”时停止,期间累计4个”1”,故连续签到天数为4。
遍历原理

- 位运算原理:
- 与运算:数字与1做与运算(num & 1)可得到最低位的值
- 右移运算:数字右移1位(num >> 1)可丢弃已处理的最低位
- 遍历过程:
- 先与1运算获取当前最低位
- 然后右移1位准备处理下一位
- 循环直到遇到0为止
public Result signCount() {
// 1.获取当前登录用户
Long userId = UserHolder.getUser().getId();
// 2.获取日期
LocalDateTime now = LocalDateTime.now();
// 3.拼接key
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
String key = USER_SIGN_KEY + userId + keySuffix;
// 4.获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth();
// 5.获取本月截止今天为止的所有的签到记录,返回的是一个十进制的数字 BITFIELD sign:5:202203 GET u14 0 List<Long> result = stringRedisTemplate.opsForValue().bitField(
key,
BitFieldSubCommands.create()
.get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0)
);
if (result == null || result.isEmpty()) {
// 没有任何签到结果
return Result.ok(0);
}
Long num = result.get(0);
if (num == null || num == 0) {
return Result.ok(0);
}
// 6.循环遍历
int count = 0;
while (true) {
// 6.1.让这个数字与1做与运算,得到数字的最后一个bit位 // 判断这个bit位是否为0
if ((num & 1) == 0) {
// 如果为0,说明未签到,结束
break;
} else {
// 如果不为0,说明已签到,计数器+1
count++;
}
// 把数字右移一位,抛弃最后一个bit位,继续下一个bit位
num >>>= 1;
}
return Result.ok(count);
}11.4 额外加餐:基于Bitmap解决缓存穿透的方案
一、缓存穿透问题回顾
缓存穿透,指的是请求查询的数据在数据库和Redis中均不存在的场景。这类请求会绕过缓存直接冲击数据库,若被恶意利用(如批量发起不存在的ID查询),可能构成对系统的攻击,导致数据库压力骤增。
二、传统解决方案及局限性
针对缓存穿透,常见的基础解决方案存在明显适用边界,具体如下:
| 解决方案 | 核心逻辑 | 局限性 |
|---|---|---|
| 合法性校验(ID < 0) | 对请求参数(如ID)做基础范围校验,直接拦截明显非法的请求(如负数ID) | 仅能拦截“格式/范围非法”的请求,无法应对“ID在合法范围但实际不存在”的场景(如ID=1000是合法格式,但数据库中无此数据) |
| 空值缓存 | 若数据库查询结果为空(即数据不存在),仍将该空结果以“键-空值”的形式存入Redis | 仅对“相同ID”的重复请求有效,若攻击者发起大量“不同的不存在ID”请求,仍会触发Redis空值缓存、数据库查询的全链路流程,无法从根本上避免数据库压力 |
三、基于Bitmap的优化方案
为解决传统方案的局限性,我们引入Bitmap(位图) 结构,利用其“高效存储、快速判断”的特性,实现对“数据是否存在”的前置拦截。
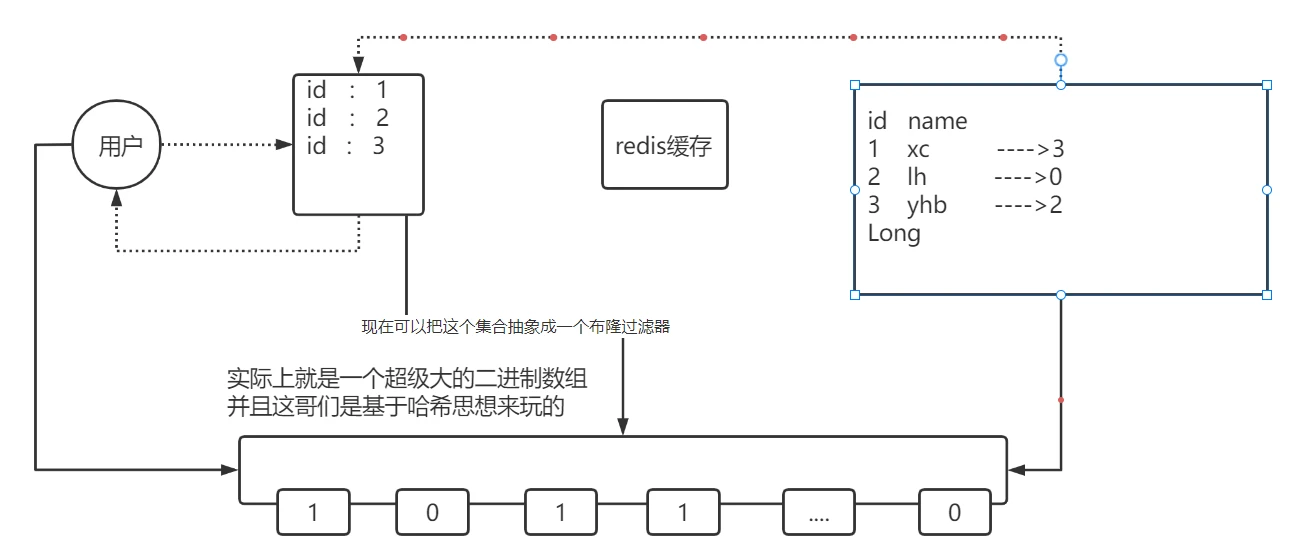
1. 核心原理
Bitmap本质是一个二进制数组(每个元素仅占1bit,取值为0或1),我们通过以下规则映射“数据库数据是否存在”:
- 1:表示对应位置映射的ID在数据库中存在;
- 0:表示对应位置映射的ID在数据库中不存在。
通过“哈希算法”将数据库中的合法ID映射到位图的具体索引位置,后续请求只需通过相同算法校验位图对应位置的取值,即可快速判断数据是否存在,无需查询数据库。
2. 具体实现步骤
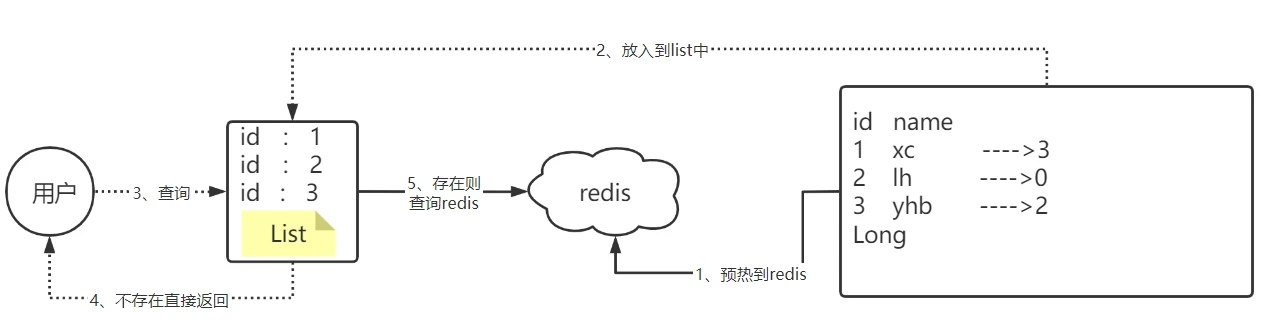
步骤1:初始化Bitmap(数据预热)
- 遍历数据库中所有合法的ID(如商品ID、用户ID等);
- 定义Bitmap的总大小(需根据实际ID范围合理设定,避免哈希冲突过于频繁);
- 对每个合法ID执行哈希计算:
索引位置 = ID % Bitmap总大小; - 将Bitmap中“计算得到的索引位置”的值设为1(标记该ID存在);
- 将初始化完成的Bitmap存入Redis(Redis原生支持Bitmap数据类型,可通过
SETBIT命令操作)。
步骤2:请求拦截校验
当用户发起数据查询请求时,优先通过Bitmap校验数据是否存在,流程如下:
- 接收用户请求的目标ID;
- 对目标ID执行与步骤1相同的哈希计算:
索引位置 = ID % Bitmap总大小; - 通过Redis的
GETBIT命令查询Bitmap中该索引位置的取值:- 若取值为0:直接返回“数据不存在”,无需查询Redis缓存或数据库,彻底拦截穿透请求;
- 若取值为1:说明该ID“可能存在”(需考虑哈希冲突),继续走正常流程(查询Redis缓存 → 缓存未命中则查询数据库)。
3. 方案优势:解决“大ID集合”的存储问题
传统方案中,若直接用List存储所有合法ID,当数据量巨大时(例如2011年淘宝商品总量已超10亿个),List的存储空间会非常庞大(每个ID按8字节计算,10亿个ID需占用约8GB内存)。
而Bitmap通过“1bit存储1个状态”的特性,极大压缩存储空间:同样存储10亿个ID的存在状态,Bitmap仅需约125MB内存(10亿 bit = 10亿 / 8 / 1024 / 1024 ≈ 125MB),存储效率提升约64倍。
4. 关键注意点:哈希冲突与误差率
使用Bitmap方案需重点关注哈希冲突问题:不同的ID通过“ID % Bitmap总大小”计算后,可能得到相同的索引位置。此时若其中一个ID存在(对应位置设为1),会导致另一个不存在的ID校验时也显示“取值为1”,从而产生“误判”,即误差率。
降低误差率的核心思路是合理设置Bitmap大小:Bitmap总大小越大,不同ID映射到同一索引的概率越低,误差率越小;反之,Bitmap越小,误差率越高。实际应用中需根据业务对“误判容忍度”和“内存成本”的权衡,选择合适的Bitmap大小。
四、方案示意图
(图:基于Bitmap的缓存穿透拦截流程)
(图:Bitmap中ID的哈希映射与状态标记)